Features:
Introducing csvdedupe
Quickly de-duplicating files from the command line
(Graphic by Aya O’Connor)
Every year in Chicago, businesses pay 10 million dollars to lobbyists to represent their interests. What do these lobbying businesses get back in contracts and payments?
It’s possible to answer that question with data the city has put on their open data portal. It’s possible to link the data on contracts with the data on lobbyists clients. However, between the two datasets there are no unique identifiers, instead we have the names and addresses of vendors and the names and addresses of lobbyist clients. We can use this information to link the two datasets, but these data were collected by different agencies and there were recorded with variations in spelling abbreviations, misspellings, and typos.
These subtle differences have made linking data boring, tedious, and extensive work, and has meant that journalists on a deadline often can’t get the answers to their questions. While, journalists have access to more complete and timely data than ever before, the data is often not in a shape to answer our questions.
What if there was a tool to turn questions like these from possible to answer to practical or even easy?
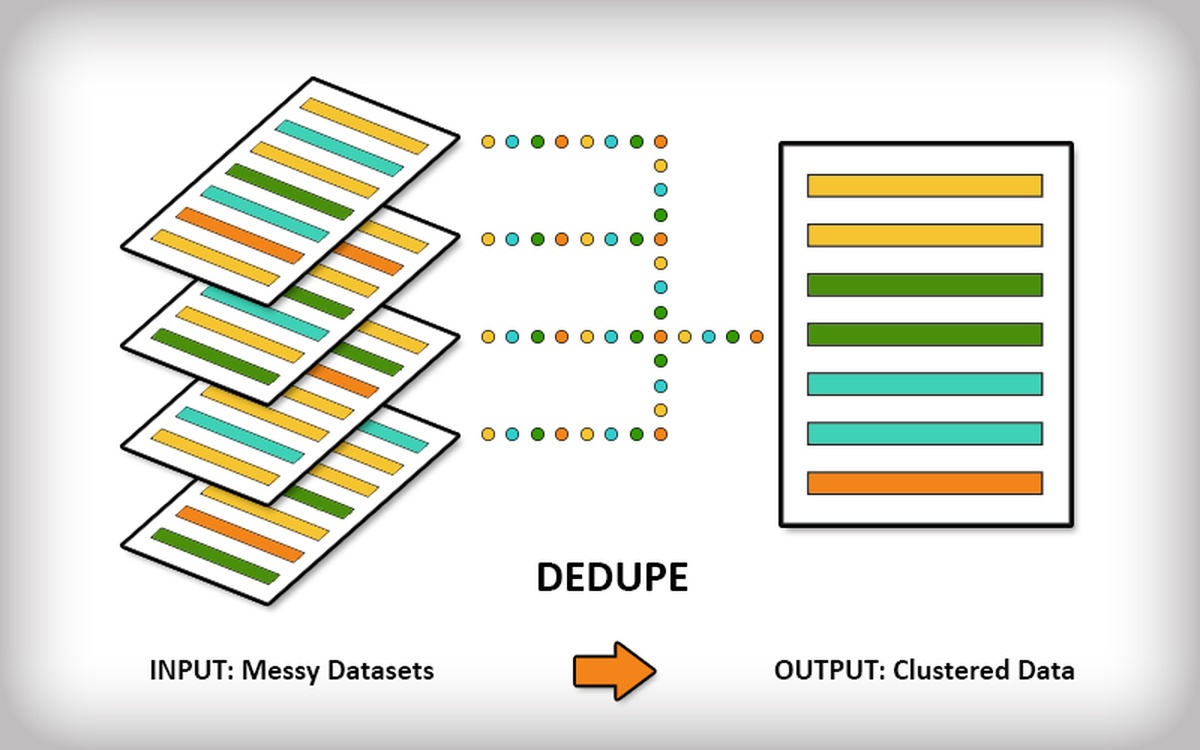
Enter csvdedupe, an open source command line tool for de-duplication and entity resolution. Simply feed it a csv file (comma separated values), the list of columns you want it to pay attention to and some training data (more on this below) and it will output a file telling you what rows it thinks are the same.
How It Works
csvdedupe is built on top of dedupe, an open source python library that we built to generically de-duplicate any kind of database or flat file. It builds on an entire field of academic computational research and based closely on a Ph.D. dissertation by Mikhail Yuryevich Bilenko called Learnable Similarity Functions and their Application to Record Linkage and Clustering.
As we hinted above, the library uses some powerful string comparators, machine learning algorithms and human input to determine the best set of field weights and blocking rules for each dataset. This is the secret sauce of dedupe and csvdedupe—you actually train the program to best identify duplicates for that particular dataset.
Once you’ve given it enough examples (say 10 positive matches and 10 negative), it will apply the rules it learned to the rest of your data, break it into thousands of blocks to quickly process it and output a csv with grouped records of two or more that dedupe thinks refer to the same thing.
UNIX STYLE
One of the big caveats to working with csvdedupe is manipulating csv files. Not wanting to reinvent the wheel with this, we built our tool to be modular and handle deduping really well, but leave the csv manipulation to libraries like csvkit that already solve that problem really well. csvdedupe supports piping via STDIN and STDOUT so you can chain it with multiple tools.
Design Tradeoffs
In order to make csvdedupe easy to use, we couldn’t have it do everything that the dedupe library does. The main thing we compromised is the size of data that dedupe can handle. We have to keep all the data in memory with csvdedupe, which limits the size of the data to few hundreds of thousands of rows. The dedupe library can handle larger data, and if you have bigger data check out this example of deduplication campaign contributions in Illinois.
What We Need
What we need now is for you guys to test and use this thing. Specifically:
If you have big, messy data sets you want to deduplicate, try out csvdedupe and tell us how it worked (or didn’t) for your use case. Also, follow our walkthrough for deduplicating multiple files from different sources.
If you notice any bugs, or have a feature request for csvdedupe, please open an issue on our Github repo.
Join our Google group for dedupe and help us build a community around these tools.
Credits
-
Derek Eder
Derek Eder has been building websites in Chicago since 2005. He is the owner of DataMade, LLC, an open government and open data web consulting company, co-founder of Open City, a collective that makes civic apps with open data, and organizer for OpenGov Chicago, a monthly Meetup group that promotes open data and open government in Chicago and Cook County.
-
Forest Gregg
Forest Gregg is a Ph.D. student in sociology specializing in computational methods. He has collaborated with Derek on projects on Chicago’s Street and Sanitation department, Chicago Public Schools, and the local economy. At the University of Chicago, Forest organized the Computational Social Science Workshop as well as the methods course “Computing for Social Scientists.”


