Learning:
Know Your Stats
Read Dave Stanton’s essential primer on basic statistical principles and you won’t get caught with your data pants down
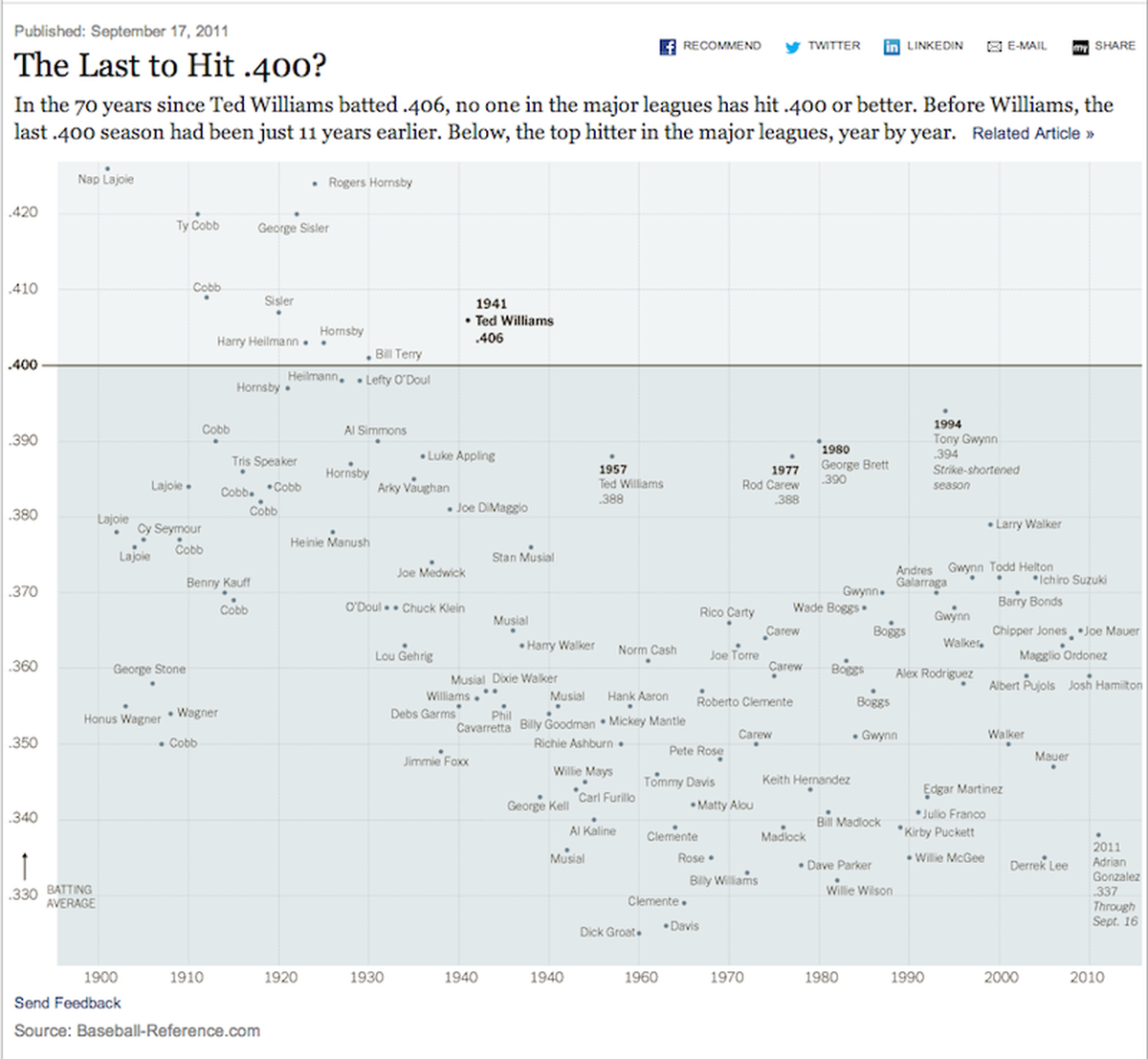
New York Times scatterplot graphic of historical batting averages
Data journalism is maturing as a discipline in which we treat databases, sensors, and cruddy government PDFs as our sources for inquiry, analysis, and explanation. The proliferation of frameworks, libraries and toolkits make crunching data easier and easier. However, we must keep in mind that it is up to us to choose tools appropriate for our data.
You can run pretty much any statistical procedure and get some output. It’s not like you’re going to get a simple NaN (not a number) error to tell you that you shouldn’t have divided by zero–one of those tenets we learned in high school. Or that a function can only have one y-value for any single x-value. Statistical models are trickier than arithmetic because there are so many assumptions regarding the nature of your data. Having access to infinite computing power and accessible toolkits does not relieve you as a human from using rational thinking to determine if the sausage you are making has meaning.
In this post, I’ll go through the fundamental statistical concepts every journalist should know before cranking up that EC2 instance, filing the FOIA, and making magic. You need to know about the assumptions of your data, more specifically the distribution of your data and the distribution of error within your data. Correlations, models, and statistical inference cannot be calculated without valid assumptions. Statistical procedures will always give you an answer. The usefulness and explanatory power of that answer is perfectly coupled with your ability to ensure assumptions are met and alternative explanations are eliminated.
Data vs. Statistics
Let’s start with the batting average in baseball. We can easily compute this by dividing hits by total plate appearances that didn’t result in a walk or hit-by-pitch. Ted Williams batted 0.406 in the 1941 season—the last player to break the 40% mark.
A bunch of data points were collected in the graph shown above but history leaves us with the 0.406 number and the 25th best batting average for a season in the history of baseball. Based on rule changes for the sacrifice fly, Williams may have hit as high as 0.419 by today’s rules. And this is important: context affects data. If sports announcers are comparing a current player to Williams, it would be a more valid comparison to use a batting average number recalculated based on today’s rules.
Takeaway 1: Context of data is critical for comparisons.
If we have complete data of every plate appearance by Williams, and then we make calculations, we are not being statisticians. Well, maybe, but super boring statisticians. That’s because batting average may be a statistic in technical terms, but it is calculated from complete data with no error.
Sampling and Margin of Error
In journalism, we use statistics to support an opinion or uncover a truth. We typically have incomplete data—either within our population or beyond our population. A population is the full collection of people or items that match certain criteria, such as all registered voters in the United States. We can’t reasonably ask every single voter to answer a question, so we draw a sample, or subset of the population. Then we use statistics to estimate the true population value, based on only knowing responses from the sample. We’re left with a point estimate and error.
Let’s relate all of this to journalism by looking at the ever-nebulous presidential approval ratings. A super-quick Google search for “presidential approval ratings” and some clicky clicky led me to McClatchy analysis with a dire-sounding headline of “McClatchy-Marist poll shows Obama tumbling in voters’ eyes.”
Get that article open in a new window and let’s do some fact checking and see how badly Obama is doing in the eyes of voters according to this poll. First, head to the methodology sidebar. 1,233 adults were surveyed, of whom 1,064 are actually voters, which is what the headline refers to. That’s approximately 0.000516% of Americans who are eligible to vote. You might be thinking that sounds like an insanely small number of people to use as representation of the opinion of America as a whole. But it’s not.
Sampling is magical stuff, and you can get pretty precise estimates of true values from even tiny percentages like this. There are a ton of sampling methodologies, but random sampling is most typically used for public opinion polls. In a random sample, each member of the population should be just as likely to be selected. The only reason we don’t actually ask a question to 200 million people is because of the insane costs and time to do so. We could if we wanted to, but instead we use a random sample.
Based on the reported methodology of this poll, we’re told there is a margin-of-error of 3%, which means the true value lies somewhere in a range 3% above and 3% below the point estimate. This is very common. In fact, statisticians often use the 3% MoE and a known population size to determine how many people to survey. This is much more cost efficient than surveying as many folks as you can afford—only survey the people or data that you have to in order to make estimations with whatever confidence you can tolerate. Pollsters typically tolerate 3% MoE at 95% confidence. This means a random sample of 1,067 people becomes the standard sample size. There is no statistical law that is met. It’s just tradition and the point of diminishing returns of reducing error by increasing sample size. (Further explanation here.) The McClatchy-Marist poll specifies a MoE at 2.8% but omits alpha level, so we’ll just go forth assuming 95% confidence.
Ok, cursory sampling theory behind us, let’s get back to our story: President Obama’s approval rating is tumbling. Jump down to paragraphs 7 and 8 of the article and let’s explore. In March 2013, the survey estimated Obama’s approval rating at 45%. The writer compares this to a previous estimated approval rating of 50% in November 2012 and concludes doom and gloom.
Both of these ratings are estimates because they were created by running a statistical procedure on a sample. They are not the true values of the population. They are data points filled with noise. You cannot trust point estimates. They give us that warm feeling of having a number, but it’s an illusion. You have to look at the margins of error and look at the ranges of probable values.
Here’s an example of how estimates work. Pretend you have a bushel of apples and selected 6 at random to get 4 red and 2 green apples. Would you say there must be 66% red apples in that bushel? No way. Let’s say you count every apple and find 66 red and 34 green apples. Ok, now we feel really sure there were 66% red. We grab another bushel and count 97 apples and get 64 red and 33 green. A ninja swoops in and steals the final three apples before we can count them. No!!!!! We’ll never know the true counts of apples. This will haunt our dreams. Now, the best we can do is estimate. The final three apples were some combination of red and green. Maybe we can sleep estimating the true number of red apples was in reality between 67 and 64. But we’ll never know if the real number was 66. The range is all that matters because we have to include our ninja-induced error in counting.
I tried to dig up the true MoE for the November 2012 poll but couldn’t find it. So, I’ll go forth assuming the pollster standard of 3%. The March 2013 poll specifies a 2.8% MoE. Now we use simple math. In the November 2012 poll, Obama’s approval rating lies somewhere in a range between 47% and 53%. To get this range, we just take the point estimate, which was 50% (the average) and subtract the margin of error (resulting in 47%) as well as adding the margin of error (resulting in 53%). For the March 2013 poll, the same procedure results in a range between 42.2% and 47.8%.
What can we say regarding Obama’s tumble from 50% approval to 48%? It’s an illusion. Notice that our ranges overlap based on our sampling error. The high end of March 2013 is higher than the low end of November 2012. There is no statistical difference in President Obama’s approval ratings. In fact, there’s a statistical possibility that Obama’s approval rating actually went up! There is no data proof to support the headline’s assertion that “Obama tumbling in voters’ eyes.”
Takeaway 2: If there isn’t separation between the ranges, there isn’t a story unless you want to publish an illusion.
Let’s go back to baseball.
Ted Williams had 606 plate appearances during the 1941 season. What if people didn’t note every event for each plate appearance? What if we only knew how Williams performed in half of his plate appearances? We could use descriptive statistics to make an educated guess at his batting average.
In our counterexample, Williams completed the full season with 606 plate appearances (the population), but we only have data from 303 plate appearances. We run our simple batting-average calculation and determine that in our 50% sample of plate appearances, Williams had a 0.406 battering average. What can we say? Did Williams actually hit 0.406 for the whole season? We can never know. Only 303 plate appearances were noted. Unless we can travel back in time, we will never know for certain Williams’ true battering average. But we do have a really good idea based on probability.
Although the point estimate of average is 0.406, we have a calculated margin-of-error +/= 5.54%. Since we have error, and we are using descriptive statistics to make an educated guess. We really need to be honest in saying we are 95% confident that Williams true batting average was between 0.351 and 0.461. That is all we can say. And on top of that, we’re only 95% sure. Based on error/noise in our sample of data (because we only have information about half of his plate appearances), there’s even a 1-in-20 (5%) chance that his true batting average isn’t even between 0.351 and 0.461. It might be higher, and he had the greatest batting season in the history of baseball. Or it might have been lower, and he only had one of the top-400 batting seasons.
Takeaway 3: Margin of error is vastly more important than average.
How is a margin of error calculated, you might ask? Here’s an Google spreadsheet I used to for calculate the +/=5.54 margin of error in the counterexample above. I also found a nice 5-minute YouTube video that describes the calculations for you. I was lazy and did not grab a raw dataset of Williams batting outcomes. Instead, I just created the correct combination of 1s (hit) and 0s (no hit) to give me a 0.406 average for 303 data points. This works with binomial outcomes but wouldn’t work with interval data like trying to estimate average length of home run balls.
When you have interval data—data that can take any and all values between a lower bound and an upper bound—you can probably just use an online calculator and get the correct answer. I even lazily went that route during my first draft of the article. However, I violated an assumption of normality, or the nature of the data as being most heavily clustered at the mean and falling off high and lower. A normal distribution is often called a bell curve, though they aren’t exactly the same. All normal distributions are bell curves, but not all bell curves are normal distributions.
It would take an entire textbook and way more eloquence than I can muster to describe all of the implications of distributions, so I’ll stick to high-level generalities. Common statistical procedures assume the mean and median are the same value and the number of observed data points decreases as you travel away from the mean aka bell-shaped. Binomial (e.g. yes and no responses) and count data (e.g. traffic deaths) violate these assumptions. There are tons of interval data sets that violate normality as well, but the problems are mitigated in large samples, so you’ll often see a requirement that the data should “approximate normalitiy” in order for techniques like linear regression to give you proper results.
Takeaway 4: Plot your data points to verify approximate normality.
In summary, Ted Williams was an amazing hitter, and almost every article ever written regarding presidential approval rating change is wrong.
Correlation and Causation
Statistics are a way to understand data by accounting for error. We say two variables have a correlation relationship when a change in one variable accounts for changes in another. We say two variables have a causal relationship when a value of one variable is set and that value has a distinct effect on what possible range of values another variable may later take. One must precede the other. Another requirement for a causal relationship is that a third variable (called an intervening variable) should not neutralize the effect of the other two.
Example time. The rate of ice cream consumption is strongly correlated with the rate of drowning fatalities. Does this mean that adage of not swimming after eating is true after all? No, in this case, it just means that these two variables increase together when another variable increases as well—temperature. Now that makes sense. We eat more ice cream in the summer when it’s hot, and we also swim more in the summer because it is hot. If more people are swimming, more people will be drowning. There is a correlation relationship here but no causal relationship.
Describing these two in contrast, it sounds like correlation is useless, right? In fact, I had the hardest time convincing a nuclear-engineer friend that correlation is a meaningful relationship. I went through the ice cream example and she said, “But they aren’t related. This doesn’t make any sense.” Our brains naturally imply causality from correlation—If I eat ice cream, I’m more likely to drown. Once we know there is no causality, it’s harder to wrap your mind around the abstract idea of a correlation as a useful statistic. Although correlations can be interesting in their own right and sometimes hilarious, you should avoid reporting on studies that only involve correlations because of the inevitable mental gymnastics your readers will perform. Despite all disclaimers, they will imply causality.
You can tell if a researcher has taken care to prove meaningful correlations and proven causality though the section of a study typically labeled as results. A researcher should go through a model building and reduction process to arrive at a reasonable simple yet explanatory model. We could build a model of census data by including every variable we have. No doubt we would find a ton of correlated variables, but we’ll never describe all of the error in a model.
Let’s say that we can use 20 census variables to predict an individual’s income. Each of the 20 variables will contribute something to understanding the error. Maybe using all of these variables helps us build a statistical model predicting income that accounts for 90% of error. It’s hard for me to describe this more granularly since you start to get into matrix algebra that is pretty much impossible to calculate yourself without being a savant. But hopefully you get the idea: build a model with 20 variables used to predict 1 other variable and understand 90% of your wrongness. A thoughtful researcher will start reducing the model by eliminating variables that don’t explain much error or perhaps explain the same error as another variable. We might be able to arrive as a more parsimonious model that has 4 census variables used to predict income and the model accounts for 85% of error. Success! We’ll never predict the true income, but we’ll have a pretty tight range of estimation and with a simplified model that is tremendously easier to explain.
Takeaway #5: Correlations are always meaningful but not necessarily useful.
In the case of temperature, ice cream and drowning there is no lying or falsehood by static stating the correlations as statistically meaningful. But you need to keep in mind that the human mind automatically applies a causal filter onto relationships. Matrix algebra may show a relationship does really exist between two arbitrary things, but the mind can’t wrap around the association without saying that a change in one causes a change in the other. In most cases, there is a third, or intervening, variable that changes and yields a change in the other two variables. Do your best to find and eliminate intervening variables from your models before you report findings in your stories. This is hard. Read through your sourced research, and find where the researchers do so. If there is no mention of intervening variables or spurious associations, that’s a red flag for the thoroughness of a causal model. If the research only reports correlations and no causality of any sort, you might want to contact the researchers and ask for help in properly describing the findings without inappropriately inferring causality to your audience.
Scaling
Let’s round out this post on common statistical mishaps by emphasizing the easiest to avoid and most tempting to make: non-zero y-axis scaling. With no prior explanation, I want you to look at this chart and think of both what is different and what feels different between these:

Zero and non-zero graphs of the same data
I’m not being very subtle. I even gave away the “what is different” in the table headers. Both include the identical data points. The numbers approximate recent Dow Jones Industrial Average levels from recent weeks. The only true difference is the y-axis is set to zero in one and not in the other. Using a zero scale is important when you are describing changes because the number of a change typically is irrelevant. Percentages and change rates (percent change as function of time) are what matter.
What feels different? The left chart gives you the “oh crap” feeling of something serious happening. The bottom has fallen out of the stock market! Dogs and cats living together! Anarchy! I’m exacerbating this through my psychological use of a red color, but this is the common design strategy to indicate a negative move in an indicator.
But the real story here is “meh.” Things happen. There are random walks, noise and adjustments typical in stock market trading. Both charts are showing a 3% drop in the market. While this isn’t nothing, it also isn’t something to cause panic. I’m going to pick on the publication Quartz a bit here because of the overly sensationalistic headline “Here’s what Ben Bernanke just did to rock the markets.”
There are some scary-looking charts in there but if you look at the real numbers, the DJIA only moved 1%. I can’t even imaging what superlative beyond “rock the markets” would have been used to describe the 23.13% single-day drop on November 4, 2008.
I did raise my concern to the author Matt Phillips about using a sensationalist headline. He said my concern regarding DJIA was valid but that some of the other market moves like bonds were more important for financial wonks. I totally understand that. DJIA isn’t an indicator used much for decision-making by financial professionals, but it is what we the general audience use for a barometer of national financial health.
Using a non-zero scale can be useful too. In my example charts, I used a 3% drop specifically to tie this scaling issue and perceived cliff-drops back to the presidential approval ratings we looked at earlier. Recall above where we threw away polling point estimates and used the upper and lower boundaries utilizing margin of error to instead look at the range of statistically possible values. A “drop” from 50% to 48% in a point estimate did not give us any evidence of a true decrease in the true national approval rating. How do we know when there is enough of a move? Recall it’s just basic addition. Average1 — MoE > Average2 + MoE. Here’s a chart to illustrate:

Appropriate use of a non-zero scale
The red line indicates our point estimates—the presidential approval rating as typically reported. Green represents the upper bound of our margin of error (+/- 3% at 95% confidence). Blue represent the lower bound of margin of error. I used a non-zero scaling on the y-axis so that we can see the horizontal lines across in order to compare the three lines to each other instead of comparing (or instinctively applying a comparison) between a line and the x-axis itself. This is a proper use of non-zero y-axis scaling because it doesn’t distort the data for our specific question: When can we say a true drop in presidential approval rating has occurred?
Our arithmetic of +/- 3 is now plotted so we just look for the horizontal line that has a lower green y-value than any of our blue y-values. We can confidently say that presidential approval dropped between our 1st poll and our 8th poll as well as between our 2nd poll and our 9th poll.
We can confidently say presidential approval rating has dropped, but our context of a drop over the time period of eight polls is immensely different than a drop between two polls. With that much time involved, it makes the job impossible for talking heads to pontificate on what single event, speech or flap caused this precipitous drop. The true change most likely correlates with big-picture economic indicators and not anything specific the President has done or not done. There is no direct causality, just correlation.
A Cheatsheet
I’ve tried to provide an accessible overview of the most common statistical challenges you’ll encounter as you use data in your journalistic projects. You always can find a story in data, but follow this guide to help ensure your data is practically useful:
- Statistics are merely a way to estimate a true value by accounting for error within a sample of data.
- You can’t draw a sample and then conveniently discard all of the error regardless of how much you want a cut-and-dried explanation.
- There are correlations in so many things that, while being statistically useful, aren’t practically meaningful.
- The human mind instinctively interprets correlation as causality as a way to make sense of the world.
- Tread carefully to avoid leading your audience to draw invalid conclusions.
Note: If you’re ready for further levels of complexity, Dave wrote a post on his site about the uses and misuses of transforms.
People
Credits
-
 Dave Stanton
Dave Stanton
Dave Stanton is a software architect and technical coach. Currently he works with teams to integrate quality, scalability, security, and accessibility into enterprise mobile and cloud projects. He earned a Ph.D. from the University of Florida by researching the behavioral and cognitive effects of interface design.


