Learning:
Public Info Doesn’t Always Want to Be Free
Matt Waite on the ethics of a news app: Tampa Bay Mugshots

TampaBay.com’s Mug Shots app
In 2009, a senior web editor asked me and another developer a question: could our development group build a new news application for Tampabay.com that displayed a gallery of mug shots? Stories about goofy crimes with strange mug shots were popular with readers. The vision, on the part of management, was a website that would display the mugshots collected every day from publicly available websites by two editors—well paid, professional editors with other responsibilities.
Newsrooms are many things. Alive. Filled with energy. Fueled by stress, coffee and profanity. But they are also idea factories. Day after day, ideas come from everywhere. From reporters on the beat. From editors reading random things. From who knows where. Some of them are brilliant. Some would never work. Most need more people and time than are available. And some are dumber than anyone cares to admit.
We thought this idea was nuts. Why would we pay someone, let alone an editor, to fetch mug shots from the Internet? Couldn’t we do that with a scraper?
If only this were the most complex question we would face.
Because given enough time and enough creativity, scraping a mug shot website is easy. You need to recognize a pattern, parse some HTML and gather the pieces you need. At least that’s how it should work. Police agencies that put mugs online usually buy software from a vendor. Apparently, those vendors enjoy making horrific, non-standard, broken-in-interesting-and-unique-ways HTML. You’ll swear. A lot. But you’ll grind it out. And that’s part of the fun. Scraping isn’t any fun with clean, semantic, valid HTML. And scraping mug shot websites, by that definition, is tons of fun.
The complexity comes when you realize the data you are dealing with represent real people’s lives.
Problems
The first problem we faced, long before we actually had data, was that data has a life of its own. Because we were going to put this information in front of a big audience, Google was going to find it. That meant if we used our normal open door policy for the Googlebot, someone’s mug shot was going to be the first record in Google for their name, most likely. It would show up first because most people dont actively cultivate their name on the web for visibility in Google. It would show up first because we know how SEO works and they dont. It would show up first because our site would have more traffic than their site, and so Google would rank us higher.
And that record in Google would exist as long as the URL did. Longer when you consider the cached versions Google keeps.
That was a problem because here are the things we could not know:
- Was this person wrongly arrested?
- Was this person innocent?
- Were the charges dropped against this person?
- Did this person lie about any of their information?
The Googlebot

Results of saying no to the Googlebot
So it turned out to be very important to know the Googlebot. It’s your friend…until it isn’t. We went to our bosses and said words that no one had said to them before: we did not want Google to index these pages. In a news organization, the page view is the coin of the realm. It is—unfortunately—how many things are evaluated when the bosses ask if it was successful or not. So, with that in mind, Google is your friend. Google brings you traffic. Indeed, Google is your single largest referrer of traffic at a news organization, so you want to throw the doors open and make friends with the Googlebot.
But here we were, saying Google wasn’t our friend and that we needed to keep the Googlebot out. And, thankfully, our bosses listened to our argument. They too didn’t want to be the first result in Google for someone.
So, to make sure we were telling the Googlebot no, we used three lines of defense. We told it no in robots.txt and on individual pages as a meta tag, and we put the most interesting bits of data into a simple JavaScript wrapper that made it hard on the bot if the first two things failed.
The second solution had ramifications beyond the Googlebot. We decided that we were not trying to make a complete copy of the public record. That existed already. If you wanted to look at the actual public records, the sheriff’s offices in the area had websites and they were the official keeper of the record. We were making browsing those images easy, but we were not the public record.
That freedom had two consequences: it meant our scrapers could, at a certain point and given a number of failures, just give up on getting a mug. Data entered by humans will be flawed. There will be mistakes. Because of that, our code would have to try and deal with that. Well, there’s an infinite number of ways people can mess things up, so we decided that since we were not going to be an exact copy of the public record, we could deal with the most common failures and dump the rest. During testing, we were getting well over 98% of mugs without having to spend our lives coding for every possible variation of typo.
The second consequence of the decision actually came from the newspapers lawyers. They asked a question that dumbfounded us: How long are you keeping mugs? We never thought about it. Storage was cheap. We just assumed we’d keep them all. But, why should we do that? If we’re not a copy of the public record, we dont have to keep them. And, since we didnt know the result of each case, keeping them was really kind of pointless.
So, we asked around: How long does a misdemeanor case take to reach a judgement? The answer we got from various sources was about 60 days. From arrest to adjudication, it took about two months. So, at the 60 day mark, we deleted the data. We had no way of knowing if someone was guilty or innocent, so all of them had to go. We even called the script The Reaper.
We’d later learn that the practical impacts of this were nil. People looked at the day’s mugs and moved on. The amount of traffic a mug got after the day of arrest was nearly zero.
Data Lifetimes
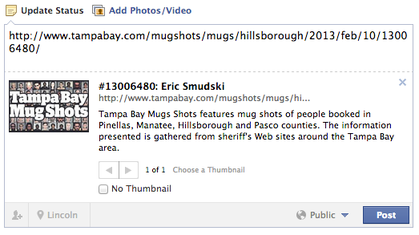
Mug Shots in a Facebook news feed.
The life of your data matters. You have to ask yourself, Is it useful forever? Does it become harmful after a set time? We had to confront the real impact of deleting mugs after 60 days. People share them, potentially lengthening their lifetime long after they’ve fallen off the homepage. Delete them and that URL goes away.
We couldn’t stop people from sharing links on social media—and indeed probably didn’t want to stop them from doing it. Heck, we did it while we were building it. We kept IMing URLs to each other. And that’s how we realized we had a problem. All our work to minimize the impact on someone wrongly accused of a crime could be damaged by someone sharing a link on Facebook or Twitter.
There’s a difference between frictionless and unobstructed sharing and some reasonable constraints.
We couldn’t stop people from posting a mug on Facebook, but we didn’t have to make it easy and we didn’t have to put that mug front and center. So we blocked Facebook from using the mug as the thumbnail image on a shared link. And, after 60 days, the URL to the mug will throw a 404 page not found error. Because it’s gone.
We couldn’t block Google from memorializing someone’s arrest, only to let it live on forever on Facebook.
You Are a Data Provider
The last problem didn’t come until months later. And it came in the middle of the night. Two months after we launched, my phone rang at 1 a.m. This is never a good thing. It was my fellow developer, Jeremy Bowers, now with NPR, calling me from a hotel in Washington DC where he was supposed to appear in a wedding the next day. Amazon, which we were using for image hosting, was alerting him that our bandwidth bills had tripled on that day. And our traffic hadn’t changed.
What was going on?
After some digging, we found out that another developer had scraped our site—because we were so much easier to scrape than the Sheriff’s office sites—and had built a game out of our data called Pick the Perp. There were two problems with this: 1. The game was going viral on Digg (when it was still a thing) and Reddit. It was getting huge traffic. 2. That developer had hotlinked our images. He/she was serving them from our S3 account, which meant we were bearing the costs. And they were going up exponentially by the minute.
What we didn’t realize when we launched, and what we figured out after Pick the Perp, was that we had become data provider, in a sense. We had done the hard work of getting the data out of a website and we put it into neat, semantic, easily digestible HTML. If you were after a stream of mugshots, why go through all the hassle of scraping four different sheriff’s office’s horrible HTML when you could just come get ours easily?
Whoever built Pick the Perp, at least at the time, chose to use our site. But, in doing so, they also chose to hotlink images—use the URL of our S3 bucket, which cost us money—instead of hosting the images themselves.
That was a problem we hadn’t considered. People hotlink images all the time. And, until those images are deleted from our system, they’ll stay hotlinked somewhere.
Amazon’s S3 has a system where you can attach a key to a file that expires after X period of time. In other words, the URL to your image only lasts 15 minutes, or an hour, or however long you decide, before it breaks. It gives you fine grained control over how long someone can use your image URL.
So at 3 a.m., after two hours of pulling our hair out, we figured out how to sync our image keys with our cache refreshes. So every 15 minutes, a url to an image expired and Pick the Perp came crashing down.
While the Pick the Perp example is an easy one—it’s never cool to hotlink an image—it does raise an issue to consider. Because you are thinking carefully about how to build your app the right way doesn’t mean someone else will. And it doesn’t mean they won’t just go take your data from your site. So how could you deal with that? Make the data available as a download? Create an API that uses your same ethical constructs? Terms of service? All have pros and cons and are worth talking about before going forward.
Ethical Data
We live in marvelous times. The web offers you no end of tools to make things on the web, to put data from here on there, to make information freely available. But, we’re an optimistic lot. Developers want to believe that their software is being used only for good. And most people will use it for good. But, there are times where the data you’re working with makes people uncomfortable. Indeed, much of journalism is about making people uncomfortable, publishing things that make people angry, or expose people who don’t want to be exposed.
What I want you to think about, before you write a line of code, is what does it mean to put your data on the internet? What could happen, good and bad? What should you do to be responsible about it?
Because it can have consequences.
On Dec. 23, the Journal News in New York published a map of every legal gun permit holder in their home circulation county. It was a public record. They put it into Google Fusion Tables and Google dutifully geocoded the addresses. It was a short distance to publication from there.
Within days, angry gun owners had besieged the newspaper with complaints, saying the paper had given criminals directions to people’s houses where they’d find valuable guns to steal. They said the paper had violated their privacy. One outraged gun owner assembled a list of the paper’s staff, including their home addresses, telephone numbers, email addresses and other details. The paper hired armed security to stand watch at the paper.
By February, the New York state legislature removed handgun permits from the public record, citing the Journal News as the reason.
There’s no end of arguments to be had about this, but the simple fact is this: The reason people were angry was because you could click on a dot on the map and see a name and an address. In Fusion Tables, removing that info window would take two clicks.
Because you can put data on the web does not mean you should put data on the web. And there’s a difference between a record being “public” and “in front of a large audience.” So before you write the first line of code, ask these questions:
- This data is public, but is it widely available? And does making it widely available and easy to use change anything?
- Should this data be searchable in a search engine?
- Does this data expose information someone has a reasonable expectation that it would remain at least semi-private?
- Does this data change over time?
- Does this data expire?
- What is my strategy to update or delete data?
- How easy should it be to share this data on social media?
- How should I deal with other people who want this data? API? Bulk download?
Your answers to these questions will guide how you build your app. And hopefully, it’ll guide you to better decisions about how to build an app with ethics in mind.
About the Author
Matt Waite is a professor of journalism at the University of Nebraska-Lincoln, founder of the Drone Journalism Lab and co-founder of Hot Type Consulting LLC, a web development firm. From 2007-2011, he was a programmer/journalist for the St. Petersburg Times where he developed the Pulitzer Prize-winning PolitiFact.
You can also listen to a podcast recorded in 2010 about the controversy when Tampa Bay Mug Shots was live.
People
Credits
-
 Matt Waite
Matt Waite
Matt Waite is a professor of practice in the College of Journalism and Mass Communications at the University of Nebraska-Lincoln and founder of the Drone Journalism Lab. Since he joined the faculty in 2011, he and his students have used drones to report news in six countries on three continents. From 2007-2011, he was a programmer/journalist for the St. Petersburg Times where he developed the Pulitzer Prize-winning website PolitiFact.


