Features:
Our Search for the Best OCR Tool, and What We Found
A side-by-side comparison of seven OCR tools using multiple kinds of documents, from Factful

Heavily redacted documents such as Carter Page’s FISA warrant are notoriously challenging for OCR tools.
Editor’s note, November 2023: This article is was published in 2019, and a lot has changed since then. We published this updated review in 2023—enjoy!
Do you need to pay a lot of money to get reliable OCR results? Is Google Cloud Vision actually better than Tesseract? Are any cutting edge neural network-based OCR engines worth the time investment of getting them set up?
OCR, or optical character recognition, allows us to transform a scan or photograph of a letter or court filing into searchable, sortable text that we can analyze. One of our projects at Factful is to build tools that make state of the art machine learning and artificial intelligence accessible to investigative reporters. We have been testing the components that already exist so we can prioritize our own efforts.
We couldn’t find single side by side comparison of the most accessible OCR options, so we ran a handful of documents through seven different tools, and compared the results.
There are a lot of OCR options available. Some are easy to use, some require a bit of programming to make them work, some require a lot of programming. Some are quite expensive, some are free and open source.
We selected several documents—two easy to read reports, a receipt, an historical document, a legal filing with a lot of redaction, a filled in disclosure form, and a water damaged page—to run through the OCR engines we are most interested in. We tested three free and open source options (Calamari, OCRopus and Tesseract) as well as one desktop app (Adobe Acrobat Pro) and three cloud services (Abbyy Cloud, Google Cloud Vision, and Microsoft Azure Computer Vision).
All the scripts we used, as well as the complete output from each OCR engine, are available on GitHub. You can use the scripts to check our work, or to run your own documents against any of the clients we tested.
The quality of results varied between applications, but there wasn’t a stand out winner. Most of the tools handled a clean document just fine. None got perfect results on trickier documents, but most were good enough to make text significantly more comprehensible. In most cases if you need a complete, accurate transcription you’ll have to do additional review and correction.
What Does the Future Hold?
The current slate of good document recognition OCR engines use a mix of techniques to read text from images, but they are all optimized for documents. They assume that material fits on a rectangular page. Most start with a line detection process that identifies lines of text in a document and then breaks them down into words or letter forms. Some use a dictionary to improve results—when a string is ambiguous, the engine will err on the side of the known word. A dictionary isn’t always enough, however, as Wesley Raabe learned as he was transcribing the 1879 edition of Uncle Tom’s Cabin.
The most promising advances in OCR technology are happening in the field of scene text recognition. As researchers and programmers look for ways to identify text in the wild (think street signs and package labels) and not just on linear documents, they’re developing tools that do a better job of identifying and interpreting text that isn’t neatly arranged in rows and paragraphs. Current OCR tools often choke on font changes, inline graphics, and skewed text—scene recognition has to accommodate all of those hurdles. Scene recognition engines have to be better about spotting letter glyphs.
There is also a good deal of promising research on techniques for pre-processing images—doing things like straightening out warped text, super resolution to boost missing details, spotting text in arbitrary locations or at odd angles, and techniques for accommodating lower resolution text.
If you’re interested in going deep on the future of OCR, Scene Text Detection and Recognition: The Deep Learning Era is an excellent survey of current literature on scene recognition. DocUNet: Document Image Unwarping via a Stacked U-Net is a good introduction to scholarly theory on image pre-processing.
How We Tested
With all that in mind, we identified a few sample documents to run through OCR systems so we could compare the results:
A receipt—This receipt from the Riker’s commissary was included in States of Incarceration, a collaborative storytelling project and traveling exhibition about incarceration in America.
A heavily redacted document—Carter Page’s FISA warrant is a legal filing with a lot of redacted portions, just the kind of exasperating thing reporters deal with all the time.
Something historical—Executive Order 9066 authorized the internment of Japanese Americans in 1942. The scanned image available in the national archives is fairly high quality but it is still an old, typewritten document.
A form—This Texas campaign finance report, from a Texas Tribune story about abuses in the juvenile justice system has very clean text but the formatting is important to understanding the document.
Something damaged— in early 2014 a group of divers retrieved hundreds of pages of documents from a lake at Ukrainian President Viktor Yanukovych’s vast country estate. The former president or his staff had dumped the records there in the hopes of destroying them, but many pages were still at least somewhat legible. Reporters laid them out to dry and began the process of transcribing the waterlogged papers. We selected a page that is more or less readable to the human eye but definitely warped with water damage.
The tools we tested support text in multiple languages—and most did at least as well with the waterlogged cyrillic documents as they did with the other English language documents we tested. If you want to test these OCR engines against your own sample documents, the Ruby scripts we used are all included in our repository.
What About Layout?
All the tools we tested will output a text file. Most will also output either JSON or hOCR files that include data about where each word and line sits on a particular page. hOCR is an open standard for representing OCR results—there are a few open source CSS and JavaScript libraries that can help you view and display hOCR formats. Check out hocrjs, hOCR Proofreader, and hOCR JavaScript for some good starting points for actually taking advantage of hOCR.
Free and Open Source Options
Calamari
Calamari is built on TensorFlow, an open-source machine learning library, which allows Calamari to take advantage of TensorFlow’s neural network capacity. It’s relatively straightforward to use, but it comes with some tricky dependencies. Because Calamari only does text recognition, you have to use another engine (they recommend OCRopus) to increase contrast, deskew, and segment the images you want to read. OCRopus requires Python 2 and Calamari is written in Python 3—not an insurmountable obstacle but one to be alert to.
Pricing: Calamari is free and open source software.
OCRopus
OCRopus is a collection of document analysis tools that add up to a functional OCR engine if you throw in a final script to stitch the recognize output into a text file. OCRopus will output hOCR.
OCRopus requires Python 2.7 so you probably want to use virtualenv to install it and manage dependencies. We had hiccups using the installation instructions in the Readme file, but found workable installation instructions hiding in an issue. You’ll also need to follow some specialized instructions to get matplotlib running in a Python 2.7 virtualenv.
Dan Vanderkam’s blog post about his experiences with OCRopus is also helpful.
OCRopus needs higher resolution images than the other OCR engines we tested—you’ll see a lot of errors if your resolution is below 300 dpi. Unlike most tools we tested, OCRopus won’t catch documents that are sideways or upside down, so you’ll need to make sure your pages are oriented correctly.
Note: We ran our test documents through the original OCRopus. Nvidia hired OCRopus developer Thomas Breuel to rebuild the tool to take advantage of advances in neural network learning, and he recently released that work as ocropus3. Early reports suggest that ocropus3 is significantly more reliable than its predecessor, OCRopus.
Kraken
Kraken is a turnkey OCR system forked from OCRopus. Kraken does output geometry in hOCR or ALTO format. Analyzed Layout and Text Object is an XML schema for text and layout information. It’s a well developed standard but we didn’t encounter other tools that output ALTO in our testing. Kraken is just OCRopus bundled nicely, so the actual results will be on par with OCRopus results.
Pricing: OCRopus and Kraken are free and open source software.
Tesseract
Tesseract is a free and open source command line OCR engine that was developed at Hewlett-Packard in the mid 80s, and has been maintained by Google since 2006. It is well documented. Tesseract is written in C/C++. Their installation instructions are reasonably comprehensive. We were able to follow them and get Tesseract running without any additional troubleshooting.
Tesseract will return results as plain text, hOCR or in a PDF, with text overlaid on the original image.
Pricing: Tesseract is free and open source software.
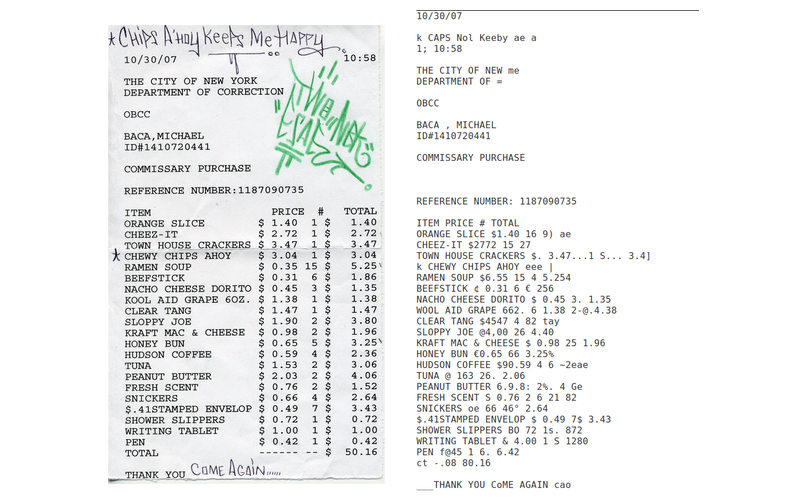
Tesseract accurately transcribed the handwritten text (“Come again…”) at the bottom of the Rikers commissary receipt. None of the tools we tested accurately captured the handwriting at the top (“Chips A’hoy Keeps Me Happy”). Tesseract definitely garbled the prices, however.
Desktop Apps
Adobe Acrobat Pro
Adobe Acrobat Pro doesn’t provide API access to their OCR tools, but they will batch process documents. Acrobat Pro only takes PDFs (no images) and only returns PDFs with searchable text inline. If you need a separate text file, you can use Docsplit to extract a plain text file from a PDF after you’ve run it through Acrobat.
Pricing: Adobe Acrobat Pro DC is a desktop app but you have to pay a recurring monthly subscription to use it—pricing ranges from $25/mo with no commitment to $15/mo with a full year commitment.

Adobe Acrobat Pro gave very garbled results on the historical document.
Cloud Services
Abbyy Cloud, Google Cloud Vision and Azure Computer Vision are commercial cloud services. The steps to setting each up can be a bit circular. Looking for a “quickstart” guide and following the steps in it turned out to be a less frustrating path than just charging ahead and assuming you can sort it out. There are a bunch of steps.
Abbyy Cloud
Of all the cloud services we tested, Abbyy Cloud is the most straightforward to set up because you aren’t setting up access to a whole cloud platform—OCR is the only thing they do. Use their Quickstart Guide to get started. Abbyy has been in the OCR business since 1993 and in addition to their Cloud API service they also sell a desktop app that starts at $200 and access to an SDK that developers can use to incorporate OCR functionality into software.
Abbyy did a better job of preserving spacing in their text only results than most of the tools we tested. In addition to plain text, Abbyy will return JSON, XML, or a PDF with the text searchable inline.
Pricing: Abbyy will let you OCR 50 pages with a free account. After that you need to sign up for either a monthly subscription or a 90-day package. Packages start at 10¢ per page for 100 pages or 6¢ per page with a $29.99 monthly subscription. Pricing goes as low as 3¢ per page when you get into the tens of thousands of pages. Their desktop app is $200, and comes without any page count restrictions.

Abbyy preserved much of the formatting on the receipt but introduced some wonky spacing. It isn’t clear why Abbyy couldn’t read the “Ramen Soup” price.
Google Cloud Vision
Google’s cloud services include an OCR tool, Cloud Vision. Of all the tools we tested, Cloud Vision did the best job of extracting useful results from the low resolution images we fed it. There are a few steps to getting it up and running, but the documentation covers them well. If you follow the instructions you should be able to get set up. If it feels like you’re going in circles, you might still be on the right track. When you create your account and first log in, you have to actually select Console from the landing page to get to the settings you need. From the console, start by creating a “project” (if it’s not your first project, the option is hiding under Select a Project. If you don’t see an option at the top left to create or select a project, try reloading the page—our Select a Project pulldown actually disappeared briefly.) Once you’ve selected (or created and then selected) a project, you will need to either search for “vision” to find the Cloud Vision API or select *APIs > enable APIs and services *and then select Cloud Vision API. However you get there, your next step is the enable button, and then create credentials—you’ll need to tell the system, again, which API we’re using. Once the project is set up, you also need to create a “Service Account”. We used “Project Owner” as the “role” for ours, but if you read the documentation you might be able to make a more precise selection choice. Once you hit Create you should be prompted to download your credentials. Save the file as credentials.json and you’re ready to run our script.
Dan Nguyen has published a few additional Python scripts that he used to compare Cloud Vision and Tesseract.
Pricing: Your first 1000 pages each month are free. After that you’ll pay $1.50 per thousand pages. In addition, Google Cloud Vision currently offers a free trial that will get you $300 in free credits, which is enough to process 200K pages in one month. When you get to 10 million pages the price drops to $0.60 per thousand pages.

Google Cloud Vision did better than any other tool on this heavily redacted FISA warrant, but still choked on an otherwise readable sentence. “1. (U) Identity of Federal Officer Making Application This application is made by” was reduced to “dentit made”.
Microsoft Azure Computer Vision
Computer Vision is Microsoft Azure’s OCR tool. It’s available as an API or as an SDK if you want to bake it into another application. Azure provides sample jupyter notebooks, which is helpful. Their API doesn’t return plain text results, however. The only way to get those is to scrape the text out of the bounding boxes. Our script or their sample scripts will do that nicely though.
There are a handful of steps that you need to follow to use Computer Vision—their quickstart guide spells them out, but you need to set up an Azure cloud account, create a “resource” (the “location” option is oddly circular, but if you stick to the default you should be okay), wait a moment for it to deploy, and then you will be able to actually go to resources to grab your credentials and the API endpoint. Add those to credentials.json in our Azure sample script and you’re ready to run it. We inexplicably got locked out of our account—reentry took more steps than it should have, but we did get back in.
Pricing: Your first 5000 pages each month are free. After that you’ll pay $1.50 per thousand pages and the per-thousand page price drops again at 1,000,000 pages and at 5,000,000 pages.

Azure seemed to do a nice job of breaking the receipt into columns, but was actually a bit erratic in its implementation. The segment shown here includes a lot of numbers from the “price” column and from the “total” column—this wouldn’t be easy to import into a spreadsheet.
All The Results in One Place
You can flip through our viewer to see how each tool did with each of the documents.
Tools We Skipped
Amazon Web Services
Amazon’s Rekognition API is primarily designed to identify text in images of signs and labels, rather than in documents. It can only pick out 50 words per image so it isn’t a great option for full pages of text.
Amazon Textract is a new service from Amazon. We applied for access to the beta but hadn’t received a response by the time we went to press.
SwiftOCR
SwiftOCR is a free and open source OCR library written on top of a machine learning library called Swift. It has some smart pre-processing built in but it is optimized for short text strings (think codes on giftcards) rather than paragraphs. SwiftOCR takes a lot more set up than other tools we looked at and it really isn’t a stand alone OCR engine—it’s designed to be built into a larger application that needs to be able to read gift cards or license plates or other short blocks of text.
Attention OCR
Attention-OCR is a free and open source TensorFlow project, based on an approach proposed in a 2017 research paper. TensorFlow is an open-source machine learning library. The authors of the original Attention-OCR paper published their proof of concept code on GitHub, while a forked version of Attention-OCR is stylistically closer to TensorFlow’s recommended usage. Both versions require extensive training to run. Attention-OCR is still very much a research project, rather than a full fledged OCR application.
Don’t Try This At Home
Or perhaps you should? All the scripts we used to run each of these tests are available in a repository on GitHub.
Organizations
Credits
-
 Ted Han
Ted Han
Ted Han was the lead technologist behind DocumentCloud from 2011 to 2018, a successful project and hosting service used widely for publication of newsworthy documents and for document analysis. Ted has been involved in open source software for 15 years, was lead developer at Investigative Reporters and Editors and taught at Missouri University School of Journalism.
-
 Amanda Hickman
Amanda Hickman
Amanda Hickman directs the Freelance Futures Initiative at AIR. She also shepherds emoji proposals with Emojination and teaches mapping and data visualization at the Berkeley Advanced Media Institute. Amanda led BuzzFeed’s Open Lab for Journalism, Technology, and the Arts from its founding in 2015 until the lab wrapped up in 2017. She has taught reporting, data analysis and visualization, and audience engagement at graduate journalism programs at UC Berkeley, Columbia University, and the City University of New York, and was DocumentCloud’s founding program director. Amanda has a long history of collaborating with both journalists, editors, and community organizers to design and create the tools they need to be more effective.


