Learning:
You Got the Documents. Now What?
Jonathan Stray’s guide to turning documents into data you can run with

This may look familiar to you
Congratulations! Your Freedom of Information request finally yielded a big brown envelope in the mail. You are the lucky recipient of a juicy leak. You’ve managed to scrape all the PDFs from that stone-age government portal. Now all you have to do is the reporting.
Would that it were so easy. Your next steps depend on what you’ve got and what you’re trying to do. You might have one page or one million pages. You could be starting with a tall stack of paper or a CSV file or anything in between. Maybe you already know exactly what you’re looking for, or maybe that anonymous tip was maddeningly non-specific. In the course of my work on the Overview document-mining software I’ve seen just about every problem that a journalist can have with a document-driven story. These are the tales of unreadable formats, heaps of paper, and late nights reading. This post is organized as a sort of flowchart, a series of questions you can ask yourself—or use to guide your colleagues who are new to the nitty gritty of data—to understand what will need to happen when the documents finally arrive.
Are the Documents on Paper?
In the summer of 2012, AP data journalist Jack Gillum wanted to know if U.S. vice-presidential candidate Paul Ryan was privately accepting the same government stimulus money that he was publicly criticizing as wasteful. Members of Congress are not subject to Freedom of Information requests, but Federal agencies are. Gillum sent a FOIA request for Ryan’s correspondence to more 300 agencies and what he got back was paper. In a blog post about the process, AP’s Mike Oreskes explains:
Over the next seven weeks, the stack of pages the government sent to Gillum steadily grew taller on the corner of his desk—to 12 inches, then to 2 feet and higher. For each file, he scanned the pages electronically and uploaded them to the AP’s internal “APDocs” DocumentCloud server.
This illustrates the first principle of working with paper documents: get them off paper. If you plan to search, analyze, collaborate, publish, or really do anything at all with your documents other than read them alone in your room, the first step is to get them scanned. Ideally they should loaded into a convenient central server—I recommend DocumentCloud as a general purpose solution, and we’ll talk more about that below.
It may surprise you how much paper is still involved in data journalism work. According to a survey of the attendees of our document mining webinar, journalists begin reporting with paper documents (as opposed to digital document files) about half the time. A lot of this comes from governments, who usually respond to Freedom of Information requests with paper. This isn’t just about antiquated systems: paper is the one format that absolutely everyone understands, and many people are still not comfortable with digital redaction tools.
Low-end scanners can now be had for under $100 but if you have any real volume of paper you’ll want something with a sheet feeder. Most copy/fax machines are also scanners, so you may already have professional equipment in your office. Or your local copy shop can scan for you. The result of scanning will be one or more document files, usually in PDF format.
Gillum scanned the documents as they came in, using his office copy machine. He ended up with almost 9000 pages which he analyzed in an early version of Overview, and found his answer:
Republican vice presidential candidate Paul Ryan is a fiscal conservative, champion of small government and critic of federal handouts. But as a congressman in Wisconsin, Ryan lobbied for tens of millions of dollars on behalf of his constituents for the kinds of largess he’s now campaigning against, according to an Associated Press review of 8,900 pages of correspondence between Ryan’s office and more than 70 executive branch agencies.
—Ryan Asked for Federal Help as he Championed Cuts, Jack Gillum, AP, October 12 2012
Do You Have Text Files or Image Files?
Scanning paper doesn’t actually produce “text” as far as the computer is concerned. It produces images. To you or me all PDF files are the same: you can open the file and view the pages. But files created by scanning paper are actually images of text.

What scanned text looks like to a computer
A digital image is stored as the brightness level of each pixel, while digital text is represented using standardized codes for each letter, digit, and symbol used in every language on Earth. If you want to search, analyze, or even cut and paste from your documents they will need to be in text format. Most journalists will run into this issue at some point, because even when documents arrive in electronic form they may actually be images.
Some file formats only store text, such as Word documents or TXT, RTF or HTML files. Some file formats only store images, such as JPEG, TIFF, GIF, or PNG. A PDF file can contain either images of text (stored as pixels) or text data (stored as character codes.)
To determine if your PDF file contains images or text, open it in your favorite viewer and try searching, selecting, and cutting and pasting the contents. If any of these work the file contains text (or it might contain both the original page images and the reconstituted text in a hidden layer.)
If your documents are images you can turn them into text through a process called OCR, an abbreviation for the delightfully archaic optical character recognition. You have many options:
- For smaller files you can try free converters such as onlineocr.net. Many online converters also support larger files for a fee.
- The best accuracy generally comes from commercial OCR software such as Abbyy or OmniPage. Acrobat Pro can also do OCR.
- The open source Tesseract package works well enough in many cases, and you can build it into custom processing scripts or applications.
- Your local copy shop will also be happy to OCR your files. They can even OCR during the scanning process if you are starting with paper.
- DocumentCloud and Overview will also OCR your files as part of the import process.
Is This Really About Numbers?
Now you have the documents in digital form, containing digital text. Sometimes you’ll want to read, search, or copy this text. In other cases it’s really the numbers you’re after.
Last summer Florida passed a law requiring all county animal shelters to make statistics available on the number of animals taken in, adopted, and euthanized. Two weeks later, WUFT reporter Ethan Magoc asked for those numbers. Only seven out of twelve counties were able to provide those numbers, demonstrating that the law was toothless. But even those counties that released the data only provided PDF files, a format that no data visualization software can load. In a PDF file, numbers are in tables which are hard for a computer to read, and that’s another obstacle. Magoc used CometDocs to extract the tables into Excel spreadsheets and create a visualization using Tableau.
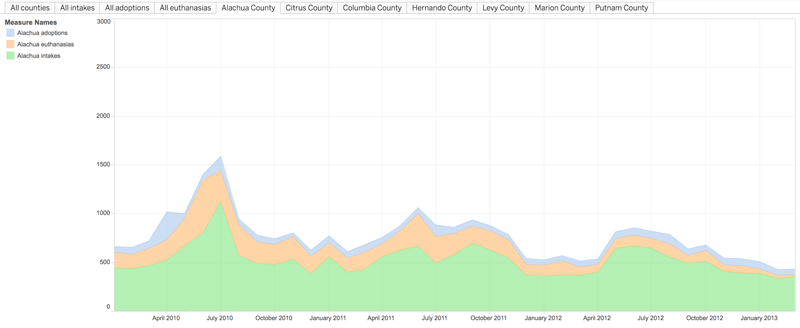
From Not All County Animal Shelters In Florida Are Following A New Law, Ethan Magoc, WUFT, July 17, 2013
This is an exceedingly common problem. You ask for data and you get documents. Joel Hoffman’s story on San Diego ethics hotline complaints is another another example of data extraction which includes the behind-the-scenes steps. In this case Hoffman was trying to visualize the topics of calls to a San Diego school board ethics hotline, but first the documents needed to be OCRd and then turned into a spreadsheet. Data extraction ends up being necessary both for simple things like publishing budget information and complicated things like analyzing MP expenses.
When the relevant data is stuck inside tables of numbers in your documents, you will need to extract this data into a spreadsheet format like Excel or a data format like CSV before you can analyze or visualize it. You will definitely need to do this conversion if you started with paper, but even digital files might be in unusable formats such as PDF.
- First, try selecting the table in the document, copying it, and then pasting into Excel or Google Spreadsheets (try both, they can give different results).
- Tabula is an open-source application you can download and run, designed by data journalists specifically for extracting tables from PDF files.
- There are number of free online services that might work, such as PDF to Excel, cometdocs, and Zamzar.
- If none of that works, you can try commercial tools such as AbleToExtract ($99 US) or Monarch Professional ($2,068 US).
Different techniques apply if your documents are HTML files, either stored on your computer or available online. Cut and paste often works, and there are also browser extensions such as Scraper that allow you to select a table on the page and spit out data. Tools such as Outwit Hub can handle more complex HTML processing tasks, including automated scraping from multiple pages.
In the worst case getting your data into a usable format might be an odyssey in its own right, as it was for ProPublica’s Dollars For Docs update. Expect some work if you have many documents or many different table formats.
Your documents may also contain structured data that is not in tabular form. Timothy Barmann of the Providence Journal created a news application that tracks the attendance of state legislators by scraping the roll call section of the House and Senate journals, as he’s written up in detail. Getting this type of data out will often require some custom code, but not always—see below on trend stories.
Getting data out of documents that were originally data is something no one should have to do—sources should publish the data in easily usable formats, in accordance with best practices for open data. But the world is imperfect and journalists will always be working at the edges of the possible, so there are regular PDF Liberation hackathons to develop better tools.
The most mean-spirited PDF I know is the yearly Department of Defense Presidential Budget Submission, which is 700 pages of dense line items in a dozen different table formats. It should really be a database, not a document, and I don’t believe anyone has yet succeeded in extracting an overall data set from it. Still, it’s relatively easy to extract a specific table using the tools above.
How Many Documents Do You Have?
The first journalist to attempt reporting on the Wikileaks cables was David Leigh of The Guardian. The material arrived as a single 1.7GB CSV file containing 251,287 U.S. diplomatic cables from 1966 to 2010. If you’ve ever tried to open a 1.7GB file, you know you probably can’t. Microsoft Word and Excel will plain refuse. Windows Notepad and Mac TextEdit will try, but slow to a crawl. Leigh recounts the problems in his book:
Obviously there was no way he, or any other human, could read through a quarter of a million cables. Cut off from the Guardian’s network, he was unable to have the material turned into a searchable database. Nor could he call up such a monolithic file on his laptop and search through it in the normal simple-minded journalistic way, as a word processor document or something similar. It was just too big.
Harold Frayman, the Guardian’s technical expert, was there to rescue him. Before Leigh left town, he sawed the material into 87 chunks, each just about small enough and read separately. Then he explained how Leigh could use a simple program called TextWrangler to search for key words or phrases through all the separate files simultaneously, and present the results in a user-friendly form.
—WikiLeaks: Inside Julian Assange’s War on Secrecy, David Leigh, Guardian Books, 2011
Fortunately most journalism does not involve 250,000 documents. The median document set size in journalism is about 10,000 pages which is small enough that it won’t break most software, and you can read it all exhaustively if you’ve got the patience. And reporters often do. I was at the AP when the 24,199 pages of Sarah Palin emails were released—on paper, naturally—and we handled that hot story by having a dozen reporters read the emails in continuous shifts over a weekend.
But 10,000 pages is still a lot, and document sets sometimes come a lot bigger than that. Here are some tips for dealing with massive amounts of material:
- It is essential to avoid doing something manually with each document, if at all possible. Any time you find yourself doing something repetitive, try to figure out how to automate the task or do it in big batches.
- Working with a lot of data means big files or many small files or both. All software gets slower when files get larger and some software has hard size limits, such as the maximum number of rows in an Excel spreadsheet, so it can be helpful to break your material up into multiple files or extract just the parts you are interested in. Conversely, some tasks are easier if you can combine many files into one.
- Get comfortable with the command line. Command line tools handle huge data sets with ease, can be used to chop up data in various ways (see CSVKit, for example) and are designed to be combined into more complex operations. If you’re new to this world, try The Command Line Murders.
- Two commands you must absolutely know: head shows the first few lines of a file no matter how big it is, while grep searches through files. Both come installed on Mac and Linux. For Windows you will want to install a Unix-compatible command line such as Cygwin or Git Bash.
- Overview is designed specifically for large volumes of documents. The public server currently supports up to 200,000 documents per project.
That covers the technical considerations, but as the volume of material increases your reporting strategy must also become more sophisticated, especially when exhaustively reading every page is not an option—or you’re on working on a breaking news schedule. The next questions are about two complementary approaches to systematic reporting on a large set of documents.
Are You Looking for a Smoking Gun?
I’ve written elsewhere about the different kinds of document-driven story, and each requires a different approach. Sometimes only one or a few key documents will form the core of your story—the proof of wrongdoing, the relevant report, the critical line in the testimony. I call this the “smoking gun,” and your job is to find it.
Jarrel Wade’s story for the Tulsa World began with an anonymous tip: the Tulsa police department was spending millions of dollars on squad car computers that didn’t work properly. He knew there was an ongoing internal investigation, but little more until his FOIA request returned almost 7000 pages of emails. He eventually found a series of key emails documenting this bad decision and its circumstances, like this one from project manager Corporal Will Dalsing to a Panasonic sales rep:

From TPD Working Through Flawed Mobile System, Jarrel Wade, Tulsa World, June 3, 2012
Search is the essential tool for smoking gun stories. You need to be able to search the entire set of documents with one query, rather than working through the documents piecemeal. I’ve seen newsrooms build entire Rails apps just to get a document set online, but these days there’s no need for that.
- First try your operating system’s file search feature.
- You should probably be uploading your material to DocumentCloud anyway, and you can search there.
- For larger numbers of documents (thousands or more) or advanced search features use Overview. If your documents are structured records, consider Panda instead.
- If you have plain text files of some sort you can do multiple-file search in programs such as SublimeText, or even just the
grepcommand line tool. - If your documents have been OCRd (see above) they may have OCR errors. You can try varying your search terms or use fuzzy search if it’s available.
- Get comfortable with the advanced search features of whatever software you’re using. These could include boolean operators, time ranges, quoted phrases, regular expressions, the ability to search different fields in the documents (such as title versus body), and more.
If you find nothing, how do you know for sure you didn’t miss anything? It’s important to try different search techniques and to document carefully how you looked. I recommend keeping a log of the search queries you’ve tried and the results of each one. Also try reporting the story another way! Use a different tool, find another set of documents or data on the same topic, or interview sources who would know.
Are you Reporting on a Trend?
Another type of document-driven story is the trend story. That’s when you’re interested in an overall pattern—what the emails mostly talk about, whether reported incidents have increased or decreased, the patterns in reported cases of abuse. This is a different kind of reporting that a search engine will not solve.
In late 2011 I found myself with 4,500 pages of recently declassified Iraq War documents, internal State Department investigations into the actions of armed private security contractors. I knew there had been a few high-profile incidents, such as the killing of 17 Iraqi civilians in Baghdad in October of 2007. But with this trove of material—essentially a case file for every time a contractor fired their weapon—I wanted to answer a more difficult question: what were these armed contractors doing when they weren’t making headlines? Were such atrocities typical or rare?
I was looking for the overall patterns, but I had no idea what they would be. This was the problem Overview was designed to solve. After scanning and OCR I loaded the documents into Overview, which automatically sorted them by topic and gave me a visualization of the contents of each folder. I found enemy rocket attacks, air operations, and other interesting things, but mostly I found that security contractors rarely fired, and when they did they usually fired into the engines of cars.
The documents show that mostly, these contractors fired at approaching civilian vehicles to protect U.S. motorcades from the threat of suicide bombers. The documents also show how often shots were fired, and provide a window into how State Department oversight of security contractors tightened during the war.
…
The State Department told us that there were 5,648 protected diplomatic motorcades in Iraq in 2007. Our analysis found that only about 2 percent of the 2007 motorcades in Iraq resulted in a shooting.
—What did private security contractors do in Iraq?, Jonathan Stray, AP, February 21, 2012
Overview is good for trend stories because it gives you a visual representation the topics in a set of documents. The public server is free and the code is open-source.

The Overview interface
Overview can read just about any document format and comes with a script to automatically OCR your documents if needed. It applies natural language processing algorithms to automatically sort your documents into folders and sub-folders based on their topic and then provides an interactive visualization of the folders. The basic reporting strategy is to explore folders one at a time, tagging what you find, going deeper into sub-folders when you find something interesting.
That’s the technique Tyler Dukes of WRAL used when we was faced with 4,500 pages of emails from North Carolina county governments. 70,000 hungry families had gone without food stamps due to delays with a new state-wide benefits system, and Dukes wanted to know why. He explains how he used Overview to get the story—in one afternoon—in his post for Source.
This type of open-ended exploration is the most general approach. There are more specialized techniques for a particular kind of trend story which I call “categorize and count.” In this case the goal is to categorize each document according to some story-specific scheme: the document contains a report of abuse, or does not; each email discusses royalties, environmental concerns, office parties, or none of the above; the vehicle referred to is a plane, a train, or an automobile. The reporting proceeds by first creating the categories, then counting how many documents are in each category.
For their comprehensive report on America’s underground market for adopted children, Ryan McNeill, Robin Respaut, and Megan Twohey of Reuters analyzed more than 5000 messages from a Yahoo discussion group spanning a five year period. They created an infographic summarizing their discoveries: 261 different children were advertised over that time, from 34 different states. Over 70% of these children had been born abroad, in at least 23 different countries. They also documented the number of cases where children were described as having behavioral disorders or as victims of previous physical or sexual abuse. When combined with the emotional narratives of specific cases, these figures tell a powerful story about the nature and scope of the issue.
You can use Overview’s tagging features to label documents. This is faster than manual exhaustive review, because Overview sorts similar documents together and you can tag entire folders at once. Or use Overview’s advanced search to count the number of documents matching a specific query or tag them for closer review. When you’re done, you can export your documents, with their tags, to create visualizations or do further analysis.
You can also try statistical sampling techniques, just like you might do a public opinion poll by calling 1,000 randomly selected people. Rather than an exact count of the number of documents in each category, this gives an estimate plus a margin of error. I used this technique to independently estimate the number of civilian injuries and deaths in the Iraq security contractor documents, as a check to make sure my search methods were reliable.
Do You Need to Publish the Documents?
I’ve mentioned DocumentCloud several times already, and I’ll mention it a few more. It was designed just for journalists and supports many of the things you might need to do with documents: upload, OCR, search, collaboration, and publication. It’s used by just about everyone in the industry and accounts are free for journalists (including freelancers), so ask for one here.

DocumentCloud in action
DocumentCloud is really the only way to go if you need to publish some or all of your documents as part of the story. It’s easy to make individual documents or entire projects public. Everything else is private and can only be viewed by you and your designated collaborators. To publish documents, just link to the document page. Or you can embed a document viewer in your story. You can also add public or private notes and securely redact information which should not be published.
Sometimes you may have security or legal concerns that prevent you from putting documents in cloud storage. (Private documents really are private on DocumentCloud.org, but there is always the possibility of hacking or subpoenas.) If this is the case you can run your own internal DocumentCloud server for your newsroom, because the software is open source.
There are ethical and legal considerations around publishing documents, much the same issues that you might have publishing anything else. One technical point worth remembering: document files can contain information you can’t see just by viewing them. There may be metadata, such as the name of the author or the GPS location where a photograph was taken, and you have to be sure to do digital redaction properly or it might be possible to recover the information.
Keep It Simple
I’m sure that was a lot to take in. But few document reporting projects involve every one of these steps, and none of them need every one of these tools. For most stories this generic workflow will do just fine:
- If it’s on paper, scan it.
- If it’s numbers, get them out.
- If it’s big or it’s about trends, put it in Overview.
- Otherwise, just upload everything to DocumentCloud and work there.
You may discover that you need some of the specialized techniques I’ve discussed in this post, but you may not. You’ve got the documents, now go! And good luck.
Credits
-
 Jonathan Stray
Jonathan Stray
Co-founder & Advisor of Workbench. Jonathan is currently working as a research scholar at Columbia Journalism School. He has written for the New York Times, Associated Press, Foreign Policy, ProPublica, and Wired.



{kind=link}