Features:
Introducing Streamtools: A Graphical Tool for Working with Streams of Data
New and open source from the New York Times R&D Lab
We see a moment coming when the collection of endless streams of data is commonplace. As this transition accelerates it is becoming increasingly apparent that our existing toolset for dealing with streams of data is lacking. Over the last 20 years we have invested heavily in tools that deal with tabulated data, from Excel, MySQL, and MATLAB to Hadoop, R, and Python+Numpy. These tools, when faced with a stream of never-ending data, fall short and diminish our creative potential.
In response to this shortfall we have created streamtools—a new, open source project by the New York Times R&D Lab which provides a general purpose, graphical tool for dealing with streams of data. It offers a vocabulary of operations that can be connected together to create live data processing systems without the need for programming or complicated infrastructure. These systems are assembled using a visual interface that affords both immediate understanding and live manipulation of the system.
Exploring the Future
Like all projects at the Times’ R&D Lab, streamtools is designed to probe a particular future approximately three to five years away. For streamtools, this future is defined by three predictions:
Data will be provided as streams. Due to the volume of data that we’re collecting, and the sensors we use to collect it, stream-based APIs are becoming much more prevalent. Only a very small proportion of the data we collect belongs in a database. Most of it is collected by systems that emit events, like the data we generate as readers simply by browsing the web, or regular samples, like the data a thermostat collects about the temperature of a room. This data starts off life as a stream, and is efficiently delivered to whomever might want to use it as a stream. Putting a database in between the sensor and the data scientist will become an unnecessary and expensive luxury.
Using streams changes how we draw conclusions about the world. As a response to the availability of streaming data, we will start to think about our analysis, modeling, decision making, and visualization in streaming terms. This means that every new data point that arrives affects our understanding of the world immediately. This is in contrast to the more usual approach of waiting until we have a large collection of data, and only then starting our analysis. This means we will borrow techniques from the world of computer science, specifically “sketches”: algorithms that use very small computational resources to learn about high volume streams. We will adopt techniques from signal processing that study the nature of the stream itself: algorithms that allow us to calculate the stream’s rate and the subtle patterns contained therein. And we will adopt techniques from machine learning to build predictive models that are constantly updated with new information, so we can track the constantly shifting systems we are interested in.
Responsive tools will encourage new forms of reasoning. Most serious analysis tools are geared up for hypothesis testing: collecting data and building models to decide if our hypotheses are correct. This is the backbone of the scientific method and has served to provide structure to statistics and its related disciplines. Data science allows for another approach: exploratory data analysis. This approach, formalised in a type of reasoning known as abductive reasoning, allows the researcher to start with data and explore, finding those hypotheses that are supported by the data rather than the other way around. Streamtools allows for traditional hypothesis testing but also enables a creative, playful approach to exploring streams of data.
Streamtools Basics

Three connected blocks
Streamtools is flow-based: data is routed through a series of operators we call “blocks.” Each block does one particular thing: for example, counting all the messages that arrive, or filtering messages based on a “username” field. Blocks can be arranged in arbitrarily complex patterns, allowing you to design sophisticated, easy-to-read workflows without writing any code.
A simple example of a streamtools pattern is a poller. At street level, 28 floors below the R&D lab just outside the northern New York Times entrance is a Citi Bike station. We can’t quite see the station from the lab but, happily, Citi Bike provides a live data feed of all their data - so we can keep track of how many bikes are outside! It’s a rather busy station.

The Citi Bike poller
We use streamtools to poll the Citi Bike endpoint, extract the number of free bikes then connect over a websocket to make a big counter on a screen in the lab. The pattern for this is in the image above, and goes as follows:
- every 10s the ticker block emits the current time
- the map block then emits the Citi Bike url and sends it to the getHTTP block
- the getHTTP block fetches the JSON from that url containing the data for all the stations
- the unpack block splits apart the information for each Citi Bike station
- the filter block filters out all of the stations apart from the one just outside the Times
We then listen to the filter block’s websocket to create our live feed of available bikes! To make your own feed, install streamtools, and import the Citi Bike pattern.
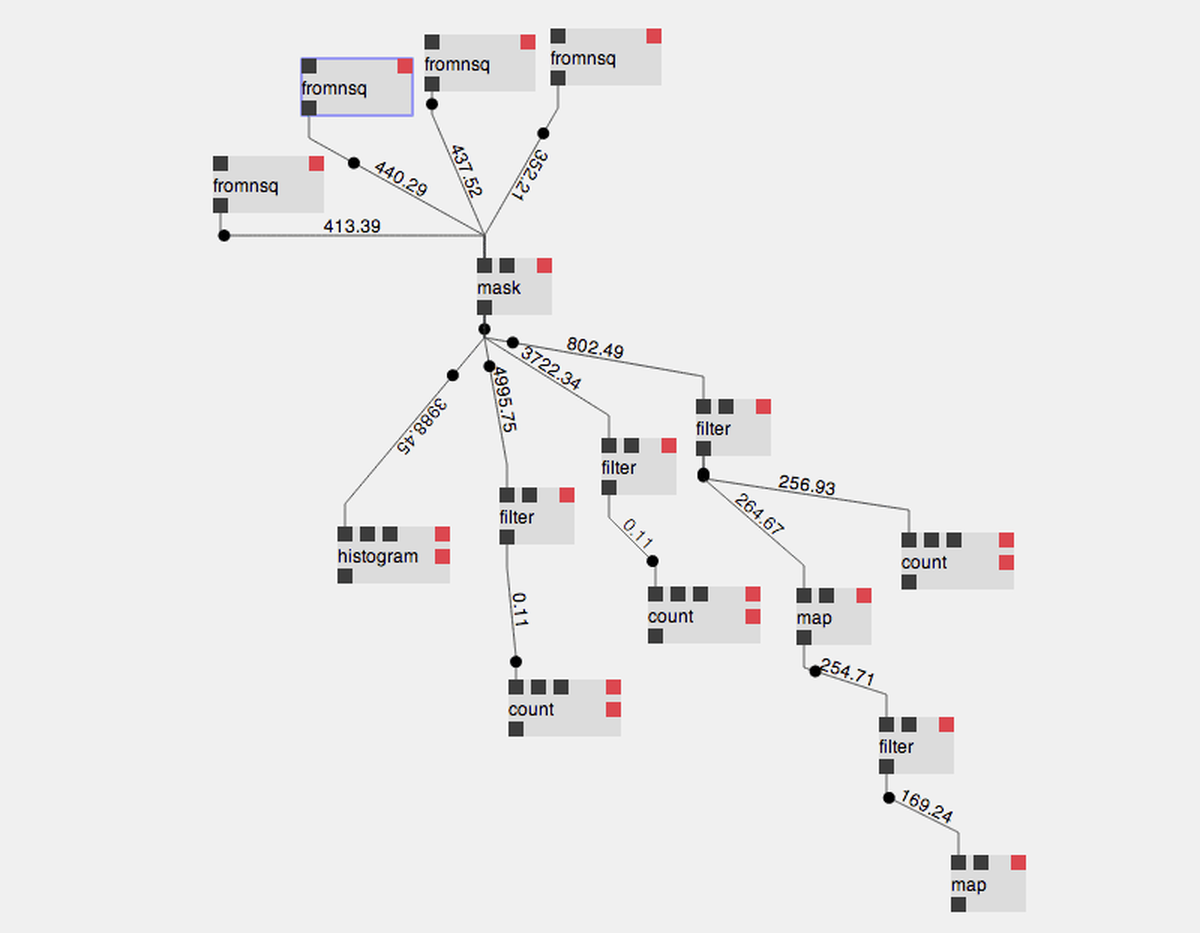
Another example is how we keep track of page events we get on the New York Times website. In the lab, these events live on an NSQ queue, which we’d like to consume to find out about the dynamics of the traffic on the site.

Making a timeseries of NYT traffic
We use streamtools to receive event data from the queue, count it, and store the resulting timeseries. The pattern for this is above, and goes as follows:
- messages flow from the NSQ queue into the count block.
- the count block keeps track of how many messages it saw over the last second
- every minute the left-most ticker block triggers a poll of the count block, which emits the count on the count block’s outbound channel.
- this count is stored in a timeseries block, which keeps 24 hours worth of data in memory.
- every hour the right-most ticker triggers a poll of the timeseries block, which emits the latest 24 hours’ worth of data into the tofile block.
- the tofile block writes that timeseries to a file, so we can graph it later.
Graphical Interface
Streamtools provides a graphical interface that runs in a browser, allowing the user to create, connect, interrogate and delete blocks.
Each connection displays an estimate of the rate of messages going through it, and the user can always look at the last message that went through that connection. Each block displays the possible inbound and outbound routes that it supports. For blocks that maintain a state, the interface provides a method of querying that state.
Streamtools’ web interface aims to be responsive and informative, meaning that you can both create and interrogate a live streaming system. At the same time, it aims to be as minimal as possible—the GUI possesses a very tight relationship with the underlying streamtools architecture, enabling users of streamtools to see and understand the execution of the system.
Programmatic Access
Streamtools provides a full, RESTful API, which you can read more about on the streamtools README. Everything in streamtools is represented as JSON - the currently running pattern, every block, every block-rule and every block-state, and it’s all queryable.
Every block has an associated websocket and long-lived HTTP stream, meaning you can easily hook streamtools up to a visualization, a product-prototype or the next stage in your analysis pipeline.
The Future of Streamtools
As a research project, streamtools is a platform to explore new algorithms and methods of analysis, as well as an exploration of graphical programming. We are looking forward to exploring these aspects of streamtools over the coming months.
We have also found that streamtools allows us to be extremely expressive when building other data-based prototypes in the lab, and so we hope that it will generally useful in the wider worlds of data science and analysis. Hence we will be maintaining streamtools as an open source project, available at https://github.com/nytlabs/streamtools.
The blocks will continue to evolve as we work through use cases at the Times. We hope to be supporting the development of testing frameworks, as well as some forms of audience analysis. We hope streamtools will allow the development of quick-to-build, targeted dashboards for individual projects, and will promote a deeper understanding of the data that runs throughout the building.
Get Involved!
Streamtools is completely open source (Apache 2 license), written in Go—a modern compiled, concurrent language. If you have ideas, concerns or discover bugs please let us know! You can always raise an issue on our issues page, and if you fancy getting your hands dirty, pull requests are always welcome!
Credits
-
Mike Dewar
data science design


