Features:
Tracking Title IX Investigations
Why we rebuilt a news app we launched just a few months earlier
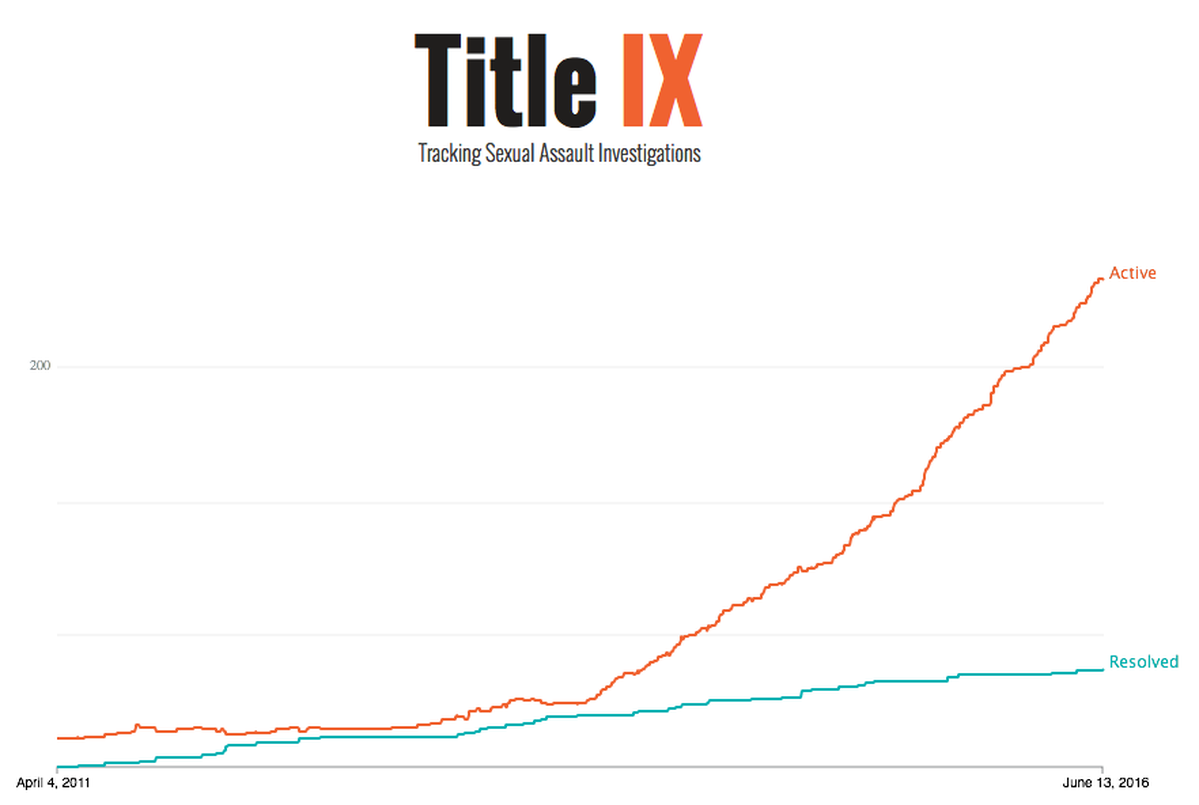
The Chronicle of Higher Education’s latest news application, which tracks the U.S. Department of Education’s investigations into how colleges handle reports of sexual assault under the gender-equity law Title IX, grew out of extensive reporting on the subject. For us, it’s a testament to the power of collaboration and experimentation—here’s how it came together, why we rebuilt it shortly after launching it, and what we learned in the process.
A Little History
In April 2011, the Education Department’s Office for Civil Rights issued a “Dear Colleague” letter that put colleges on notice: It was stepping up enforcement of the antidiscrimination law. We’ve written numerous stories looking at the fate of hundreds of federal Title IX complaints against colleges, the national conversation about campus sexual assault, and whether the stricter enforcement signals progress.
But as the government was opening more investigations, there was little information about what was actually happening. In fact, it wasn’t until May 2014 that the Education Department even named the 55 colleges that were under investigation at the time. We kept requesting updated lists, but there was no comprehensive up-to-the-minute source of colleges being investigated. So we decided to build one. The result was our Title IX tracker, which we launched in early 2016.
Getting Started
We first started talking about building the tracker a year earlier. We brought together a sizable group—maybe nine reporters, editors, and front- and back-end designers and developers—to think through what we should do. The first issue centered on what, exactly, we wanted to track. Title IX covers far more than sexual assault; it prohibits any sex discrimination in education. Did we want to broaden our look into all aspects of sex discrimination? Were we interested in tracking the thousands of complaints (filed mostly by students and advocates), or only actual investigations? What time period should we focus on?
There was an argument for including everything, but Sara Lipka, the editor who had been leading our coverage, was clear: We should keep this focused on the news. Scrutiny of how colleges handle sexual assault was what prompted the federal government to act, and was what activists and the public were most focused on. So that should be our concentration, too. Plus, there was the benefit of a manageable number of investigations—fewer than 200 at the time, starting from April 2011.
As we worked through ideas and posed questions to one another, we developed a list of assumptions and expectations about what the tracker should do. Some later proved problematic, but they gave us the blueprint to proceed. They included:
Tracking each individual investigation, or case.
Providing some context about how the issue of sexual assault had come up on that campus, including links to related news articles
Giving users a way to be alerted to updates.
Including investigation-related documents, or case files, as we got them.
Two developers were tasked with building out this first version. Ben Myers focused on the front-end design and development, while Jon Davenport built the back end in Python. Meanwhile, a group of editors and reporters got busy creating a database of cases, associating them with colleges, doing research to fill in context on each campus, and filing FOIAs to get case files.
A few things quickly became clear. There were precious few details about the investigations themselves, and due to restrictions on information that could be released, it often was not known if a high-profile report of sexual assault on a particular campus was related to an investigation there. And so we began to realize that when there were multiple investigations at a single campus—as of this writing, there are 126 such examples—we would be duplicating the campus context and the links to related articles.
And, as will surprise nobody familiar with the time it takes for FOIA requests to be fulfilled, our plan to include case files became more of an aspirational long-term goal then a short-term reality.
Nevertheless, after months of building out the database, finding links to relevant content, uploading files to DocumentCloud, writing context blurbs, tweaking the design, and copy-editing everything, it was time to publish.
Launch and Learn
The thing about clichés is, they’re often true. Case in point: The publishing of a news article often represents the final step in a long process, from pitching to reporting to writing. But for a news app, publishing is just the start of a whole new phase.

Our initial version focused on giving users a way to search for cases.
And so when we took the site live in January, we were eager not just to see the reaction of users, but to track their behavior. Would they sign up for email alerts? How would they search for cases? We baked in extensive Omniture tracking and paid close attention to how they got around the site. We included a feedback mechanism so users could tell us what they thought. What we learned was instructive and informed our next steps.
To our delight, hundreds of users signed up for alerts. That was important, as it created a way to keep our audience informed and engaged. From the analytics, we could see that users were interested in multiple, often related, campuses.
Because the tracker was completely separated from our primary site, we looked for ways to drive traffic between the two. We built a widget that we could embed in our main site to give users quick access to search the tracker. And we embedded related Chronicle stories in the tracker so readers could pursue their interest in the subject through our reporting.
Interactive widgets help ensure our news app is integrated into the main site.
Furthermore, the tracker was intended to be—had to be—active and up to date. That meant establishing workflows for keeping it current. The key was assigning tasks to specific individuals—and taking advantage of some nifty Slack features.
Because the Education Department updates (but does not automatically distribute) its list of investigations every Wednesday afternoon, we used Slack’s reminders feature to automatically post a note to our #title-ix channel every Wednesday afternoon.

We appreciate Slack reminding us each week to get the updated list of cases.
That would prompt one person to request the updated PDF, which would then be posted to the Slack channel, with the changes—if any—noted. Another member of the team would then file the appropriate FOIA requests for the case files, posting them to DocumentCloud and adding them to the tracker when some, eventually, started to come in.
Editors would update the database with the appropriate changes, mainly adding new cases or updating existing ones, to be followed by a copy editor who would make the updates live. That would trigger the automatic creation of alerts.
By defining roles and workflows, so that everyone had a job and knew what they needed to take care of, it quickly became a well-oiled machine.
Spotting Flaws
One of the features we were most excited to test was a system for alerting users to new information. We set it up so that whenever we updated a record, that would automatically create a draft alert in the database. A Slack integration posted a note in our #title-ix channel that an alert had been created and was ready to be edited. Then we could go into the Django admin, fine-tune the alert, and send it out to all subscribers. That process worked both for case-specific alerts and for our weekly roundup.
Slack makes it easy to let everyone know when an alert is ready to be edited and sent.
The system worked great, but flaws in our thinking soon became apparent. Users following a case at one university would be informed only if that specific case changed. They would not be alerted to additional cases opening up at the same university, for example.
As we kicked around ways to address this, we realized that other structural choices we had made were creating problems we hadn’t foreseen. Even though the solution to the alerts was simple (we eliminated case alerts and focused solely on weekly updates), talking through it highlighted other challenges. For example, while our use of Elasticsearch made it easy to find cases at any given college, or to search the context we wrote about each campus, finding all cases that shared an attribute was not possible.

Our first version focused on cases, not campuses. While this seemed like the sensible approach, we realized it actually made the site more difficult to use.
This was most apparent when other reporters went looking for information like how many colleges in their states were under investigation. Or even how many cases being tracked had been resolved.
All of it boiled down to a realization that our data structure—cases as the basic unit of information—was flawed. Colleges, not cases, should have been our basic unit.
Initially it made sense to make the case, each investigation, the basic unit of information. We were gathering files on individual investigations. We were tracking when they were opened and if/when they were resolved. We thought that eventually we would be able to dig deeper into investigations to better understand how they came to be, what they involved, and how they played out.
What we didn’t fully appreciate was the awkwardness of displaying multiple investigations at single colleges (some now face four or five)—and how much more information we’d often have about the campus context than about the investigations themselves. We’re filling those details in as we go, mostly through the FOIA requests.
Flipping the approach to focus on campuses didn’t eliminate the ability to show individual investigations, it just forced us to develop a new strategy. Ben Myers came up with a creative solution that made cases elements of colleges. That preserved the ability to display information specific to the case when we had it, but also allowed us to group cases together under a college.
Still, making that switch was nontrivial. It meant completely changing the structure of the database, redesigning the pages, and reworking the URL structure. We needed to reassociate hundreds of context blurbs and thousands of links from individual cases to colleges. But it was the right thing to do—and it solved other issues as well, such as the duplication of information when there were multiple investigations at a single university.
Redesigning to Reinforce Currency
The first version of the site was focused on giving users the ability to search the database. We assumed that users would want to look up a specific case or college, and the data we gathered from Omniture backed up that assumption.
But an unintended consequence was a sense that the site wasn’t current. It seemed too static for a “tracker.” To fix that, as well as to address the other issues mentioned above, we needed a redesign.
So just a couple of months after launch, we went back to work. As part of making colleges, not cases, the basic unit of content, we developed a tagging system that allowed us to group investigations by state, status (active/resolved), other other attributes, and a design solution that reinforced cases as subordinate to college pages. That led to a new side drawer that made navigating between colleges easier and faster, while an advanced search gave users the ability to execute sophisticated queries.

Focusing on colleges, not cases, as the basic unit of content helps users see what’s happening at each institution and keeps us from having to duplicate content.

Through tagging and advanced search, being able to group and find cases is easier, and satisfies a user need.
The new front page incorporated data visualizations to give a snapshot overview of current investigations, based on the latest data, as well as a log of updates to the cases being tracked.

Incorporating data visualizations into the main page gave the site a better sense of currency.
Coming on the heels of the initial launch, the relaunch (five months later) was a significant overhaul, but one that incorporated the lessons we learned to make the site stronger and more useful.
There are now nearly 300 investigations in our tracker and more than 1,000 users signed up to receive alerts. And we’re still looking for ways to make it better. For example, following the update, we added a public API so developers can automatically feed their own apps or widgets with the data we’ve collected.
Our biggest lesson: Journalism is rarely the solo sport it’s made out to be, but a news app like this one takes collaboration to a whole new level. Almost a dozen people on our staff played a role. Involving that many people can make news apps hard, but it can also make them great.
People
- Jon Davenport
- Nick DeSantis
- Sarah Henderson
- Sandhya Kambhampati
- Sara Lipka
- Kerry Mitchell
- Ben Myers
- Ben Pilkerton
- Scott Smallwood
- Andy Thomason
- Ginnie Titterton
Organizations
Credits
-
Joshua Hatch
Joshua Hatch is the Assistant Managing Editor for Data and Interactives of The Chronicle of Higher Education and The Chronicle of Philanthropy, and the president of the Online News Association.


