Features:
We’re Building a New Central Resource for Public Data
Introducing our one-stop data center for holding the powerful to account

Investigative Reporting Workshop data fellows Kiernan Nicholls (standing) and Yanqi Xu (looking up); and data intern Kimberly Cataudella. (Photo: Hadley Chittum/IRW)
Stories about conflicts of interest, influence, and accountability often require journalists to search across many different datasets, which are rarely in the same place. The Investigative Reporting Workshop created The Accountability Project to make much of that data available in one search.
The project grew out of many conversations between the late David Donald, former data editor for the Investigative Reporting Workshop, and current Workshop executive editor Chuck Lewis.
In his original proposal for the project, Donald stressed the need for data among accountability professionals.
“The key is the link among databases that provide the connections that allow us to hold the powerful accountable for their decisions and actions,” he wrote.
The Accountability Project team is working to make his idea a reality and build it into a robust search site that connects a broad catalog of public data sets. So far, we’ve uploaded hundreds of databases, accounting for more than 530 million records.
Collecting Public Data
We started with data related to money in politics and have added data on nonprofits, voters, business licensees and public employees. Our current collection is mostly federal and state government data, but we hope to add some data from counties.
Location matters, so whenever possible we’ve included addresses and made them searchable, along with names. The Federal Election Commission makes federal campaign finance data available in bulk—but omits street addresses and contributions less than $200. To get around this we reprocessed a decade of federal campaign finance contribution and expenditure records directly from the source files to add back details cut from the official bulk files.
We will continue to expand into other categories with data that focuses on people, organizations, and their locations. If you have an idea for a dataset that you think we should include, you can learn more about what we’re looking for and let us know here.
We think this project is especially important at a time when newsroom resources are limited, deadlines are tighter, and accountability journalism is needed more than ever. Ultimately, we will define success by providing resources that help generate stories and reporting that holds powerful people and institutions accountable.
Pitch a Story Idea That Uses Our Data
To help us work toward that goal, we’re accepting story pitches that draw from the data in The Accountability Project in some way, and are offering financial stipends, data support, and co-publishing and promotion for ideas that we select.
We’re accepting a wide range of pitches and are agnostic about the topic. Ideally, your story would have an accountability angle and seek to highlight an abuse of power, conflict or interest or injustice. Our main requirement is that you use The Accountability Project in some way to inform your reporting, whether it’s backgrounding a particular person or organization by searching the site or finding connections across the different data sets we have available.
We just approved our first story pitch with nonprofit newsroom Eye on Ohio and are looking forward to the stories that will emerge from this new partnership.
How We Built The Accountability Project
The project was made possible through a grant from the Reva and David Logan Foundation, which has funded our work for three years. Our team is made up of IRW staff, fellows, and consultants. Jennifer LaFleur plays traffic cop, managing students and collaborators. Jacob Fenton is the lead developer, bringing experience in large database projects, including those at the Sunlight Foundation and as a consultant on ProPublica’s Nonprofit Explorer. Our audience consultant, Cole Goins made our messages shine and has worked to keep us on track. We also have had an amazing group of interns and post-grad data fellows acquiring and standardizing data for the site.
The initial phase of The Accountability Project, a search tool that focused on data related to money in politics, was vetted by some generous members of the news technology community who agreed to test drive the site. Since then, we’ve added more categories of data and tweaked the site based on user feedback. We officially launched the site in June.
The site is built on Amazon cloud technologies: an EC2 web server, a hefty Postgres Amazon RDS database, as well as an Elasticsearch account with elastic.co.
Our data is stored as a data lake, with only a subset of fields as native Postgres columns. The full data is kept in JSONB.
The website itself is built with Django, and an administrative site lets our data fellows pull in datasets from S3 and tag the columns containing names, addresses, dates, and other key fields. The search pages are built using Svelte.js.
The data is split into names and addresses, which are searched in Elasticsearch and what we’re calling transactions, stored in PostgresSQL. A transaction might be an expenditure or a registration. Below is a detailed diagram of the architecture. Note that the “feline observer” may not be present for all search scenarios.
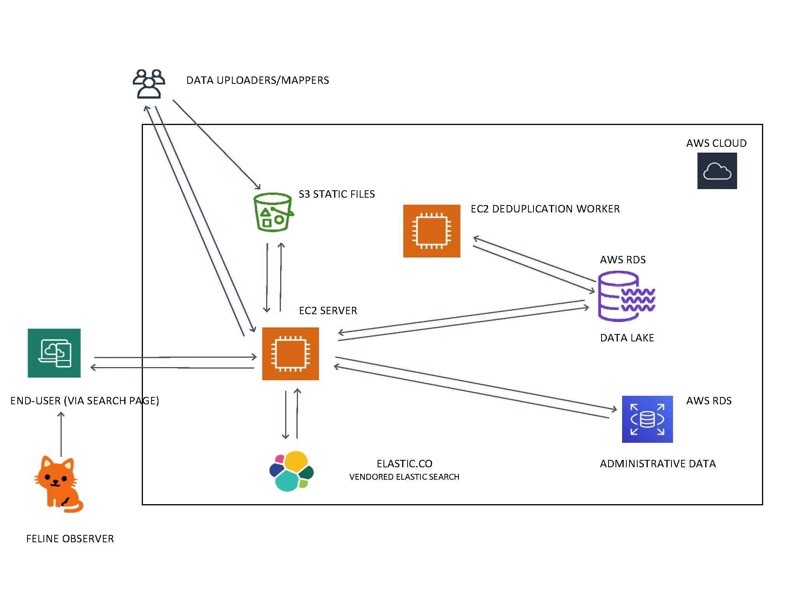
A detailed diagram of the architecture. Note that the “feline observer” may not be present for all search scenarios.
So far, the biggest stress on our database is at the data loading stage, which means we can add capacity only when needed. We’ve been loading data into a staging site, so that we can check that search results work as intended before publishing to the live site.
From the beginning of this project we knew we would be making adjustments based on technology and user feedback.
We are considering swapping out the staging and production sites with Aurora, Amazon’s cloud-based relational database service, in our next phase. Using Aurora could save money because we can often “pause” our staging site when it’s not in use.
We weren’t really sure what to expect as far as use or our own rate of data acquisition, so we reserved the annual instances and elastic contract we could afford, figuring we could re-engineer at a cheaper price point when we had a better idea of what our use would be like. The biggest thing we didn’t prepay for was storage, which has turned out to be a substantial need.
As is typical, the news technology community has been invaluable, particularly in the development stages of this project. Many folks offered to test the site and provide feedback. We’re also actively seeking to add datasets to our site, working with Workshop fellows and interns to gather and review data. We’re working to develop partnerships with data journalism programs at universities to expand our data-gathering capacity.
Challenges and Opportunities
Every stage of this project offered unique challenges. At the onset, we needed to develop a shared vision for The Accountability Project among our team, mapping out an ambitious but manageable path for what we could realistically build with our resources and timeline. This involved identifying parts of our original plan that weren’t reasonable (e.g. how much data we could reasonably wrangle), managing our own expectations, and creating a clear plan for the specific datasets we wanted to make available and searchable in our database.
Many of the databases we’ve included in The Accountability Project required filing open records requests or extracting data from documents. Reviewing hundreds of data sets with a scrappy crew of fellows and data journalists has meant a lot of hard work to gather, check, and add the data to the site. To help keep things organized and on track, we keep a log of every database from request to upload, including the name of the person responsible for it. We’re software agnostic, as long as users can create a reproducible workflow or script.
In beta, we focused on money-in-politics data. We’ve expanded our catalogue to include nonprofit data, voters, business licenses, salary data, and others. But all data is about a person or organization and allows searching by those entities, as well as by address.
Our main challenge going forward is getting folks using the site regularly and using it as a resource for accountability stories. We’re thinking of new opportunities and partnerships that could help expose more journalists to The Accountability Project and establish it as a go-to tool for reporters.
At the same time, we plan to add new features to the site, including geographical searches and the ability for users to run their own data against what is on the site. We’re also planning to conduct more user experience research to get a better understanding of how people use the site and how we can improve its functionality.
We have exciting plans for the next year and are currently seeking more funding to support our work going forward, as we continue developing The Accountability Project as an essential data resource. If you have ideas or feedback, please drop us a line: accountability@irworkshop.org.
Insights From Building The Accountability Project
For anyone else looking to take on similar projects and build new resources and tools for journalists, we have a few points of advice.
Research what else is available. What does your project do that is unique? Find people and organizations that you can partner with instead of recreating the wheel.
Understand and communicate your shared vision from the outset. We had several key personnel changes with our project, so maintaining consistency and making sure everyone had the same idea of what to expect was challenging.
Plan for the long, long term. If you want your project to live for a long time, make sure you have a sustainability plan to keep it going. It likely will take longer than you anticipate to launch. We’ve watched plenty of well-intentioned search projects die a slow death from lack of funding because it’s hard to find long-term support. We’re working to lower our operating costs, but also taking steps to make sure the data we’ve gathered helps others.
Have fun. Projects like this are an incredible amount of work. If you can’t have some enjoyment doing them, your product will not be as effective.
How You Can Help
We would love folks in the news technology community to use the site and suggest new data sets we should add or ways you think we could make the site better. Your input and feedback will help us identify new applications for The Accountability Project and opportunities to make it an indispensable tool for journalists.
We’d also love to hear about how you use the data in your reporting, or any way it’s helpful to your work. You can also pitch us a story here and contact us at accountability@irworkshop.org.
Credits
-
 Jacob Fenton
Jacob Fenton
Jacob Fenton is the lead developer of The Accountability Project. He’s worked previously as Editorial Engineer at The Sunlight Foundation, as Director of Computer-Assisted Reporting at IRW, and as a reporter and editor for newspapers in Pennsylvania and California. In 2015 he was a JSK Fellow at Stanford, where he worked on structured data extraction and machine learning.
-
 Jennifer LaFleur
Jennifer LaFleur
Jennifer LaFleur joined the Investigative Reporting Workshop as data editor in 2017. LaFleur previously was a senior editor for Reveal from The Center for Investigative Reporting, is the former director of computer-assisted reporting at ProPublica and has held similar roles at The Dallas Morning News and other newspapers. She was the first training director for Investigative Reporters and Editors and currently serves on IRE’s Board of Directors.


