Features:
How NPR Transcribes and Fact-Checks the Debates, Live
Behind the scenes of the Visuals team’s most technically complex project yet
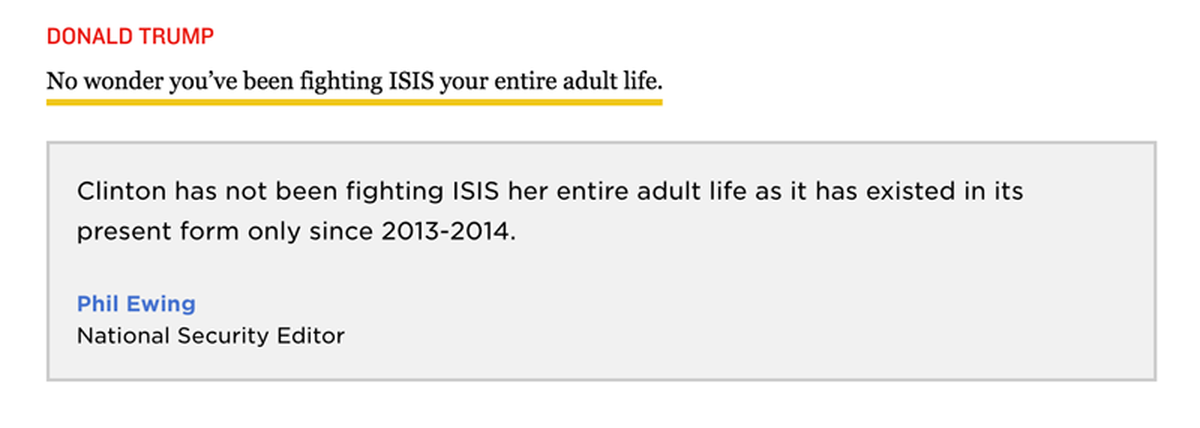
From the NPR transcript-fact-check combo package for the first presidential debate
For the presidential debate season, NPR is providing live transcripts of the debate with embedded fact checks and annotations throughout each debate night. Coordinating the workflow between live transcriptions, live fact-checking, and a live-updating page inside of our CMS was no small undertaking, resulting in what may have been our team’s most complicated technical architecture yet. I’m here to tell you all about it!
Team Structure and Workflow
On the Visuals Team, this project has combined our talents in a way we don’t always do. The core team consisted of Katie Park, Wes Lindamood, Juan Elosua, Clinton King (our current news apps intern), David Eads, and me. On the design side, Wes was responsible for design strategy and planning, and Katie was the lead designer responsible for execution of the design and user experience. On the development side, Clinton, Juan, and I all worked pretty interchangably, but Juan took the lead on parsing our live transcript and annotations and I took the lead on developing the front-end of the application. Clinton developed features on both sides of the equation. David led the team and served as product owner.
Specifically, having Wes and Katie collaborate in this way on design meant each of them could focus more on specific parts of the design process. If you divide design into “definition” and “execution,” Wes focused on definition and Katie focused on execution. That meant both Wes and Katie could explore more possibilities and, in the end, make the user experience better. On most projects, our designers have to handle both ends of the spectrum, meaning less time for exploration.
Having two designers also means there is a feedback mechanism for work that avoids “design by committee,” allowing work to move faster. Speed was important for this project, since we started working on it in earnest two weeks before the first debate.
Of course, we also collaborated heavily with our politics team in creating this system. Editor Amita Kelly was particularly indispensable in making this happen.
A Brief Technical Overview
Our application consists of six main parts, which my editor David Eads helpfully condensed into a tweet:
transcription service ←→ google app script → google doc (+18 factcheckers) ←→ server → s3 → embedded widgethttps://t.co/Dzt3a0O4rL
— David Eads (@eads) September 27, 2016
In a few more words, we’ve partnered with Verb8tm, NPR’s standard transcription partner, to provide us with a live transcript that they publish to an API throughout the night.
We wrote a Google Apps Script that consumes the transcript from the API, parses it into readable paragraphs, and appends it to a Google Doc.
Inside the same Google Doc, as new transcript comes in, an editor backreads the transcript and makes corrections as necessary. Fact checkers (we had over a dozen for the first debate) find statements to check and add their annotations in Google Docs Suggesting mode. A copyeditor edits both the transcript and the annotations. Overseeing all of this, our political editor Amita Kelly has the final say on what annotations go by approving the suggestions.
We have an Amazon EC2 server running a daemon that downloads the full Google Doc as an HTML file, parses it with copydoc, our library for cleaning the HTML from a Google Doc, then executes some custom debate-specific parsing code, and finally publishes a clean HTML file to Amazon S3.
Then, our client-side app (also hosted on Amazon S3) consumes that HTML, turns it into a virtual DOM element, and diffs it with the current state of the DOM to apply only the necessary changes to the document.
Finally, we embed this client-side app inside of our CMS, which we handle with our responsive iframe library, pym.js, and a whole lot of custom cross-domain iframe messaging to handle the animation when a user scrolls to see a new animation. We are embedding this app not only inside of npr.org, but also on member station websites across the country. To achieve this, we use the new pym-loader JavaScript Juan Elosua developed for pym version 1.0.0.
We haven’t open sourced our code yet, unfortunately. There’s some work that needs to be done to remove some private keys and things, and we, like many of you, are too busy with the rest of our elections work for the next few weeks. We promise to get it open sourced eventually, but note that having the full source probably wouldn’t help you. Our setup is custom-built around our relationship with our transcription partner, who transcribes all of NPR’s content every day. So you’re more likely to get more out of reading this post than straight-up using our code.
The Nitty Gritty
I know, I know. You’re hungry for the details. Let’s follow the same path I outlined above, from the transcript to the embedded widget.
Transcript API
Our partners at Verb8tm (whose technical support staff were among the most cooperative partners we’ve ever worked with) provided an API endpoint that returns the latest version of the transcript when requested. The endpoint publishs the transcript as an SRT file, a plain-text format for subtitles. A subtitle block comes in four parts:
- A number representing the place of the subtitle in the sequence of all subtitles
- The begin and end time of the block of text relative to the start of the subtitle
- The subtitle
- A blank line breaking subtitles apart
The API also returns a header that indicates the final caption identifier (piece one of the SRT block) in the current version of the SRT. That means we can store that number and only request anything that came after that subtitle block on subsequent requests.
The Google Apps Script
Google Apps Scripts are funny. They are essentially self-contained JavaScript environments that provide extended functionality to interact with Google services, such as, you guessed it, Google Docs. Google Apps Script projects connect with your Google account’s Google Drive. Within a project, you can have multiple scripts that all exist within the same environment. For example, we have a file that deals with parsing the SRT file, and we have another that deals with appending the parsed transcript to the Google Doc.
Using a Google Apps Script is the only way to append our new transcript chunks to a Google Doc, but it also comes with certain limitations.
In a Google Apps Script, you can create time-based triggers, meaning code can execute on a timer. It works essentially like a cron job, and just like a cron job, you can only execute once a minute. That means we can only get new transcript from the API once a minute.
So, every minute, our Google Apps Script hits the Verb8tm API. The first time it runs, it gets the entire available SRT available. It stores the last SRT ID for the next time the function runs. On subsequent runs, it sends that ID back to the API, and the API returns only the new parts of the SRT.
Once we had our SRT chunks, the Google Apps Script also has to parse SRT into readable paragraphs. Luckily, Anton Bazhenov wrote a JavaScript parser that turns an SRT block into an object a long time ago, so we use that in the script.
Next, with our parsed SRT, we have to build intelligible paragraphs. There are pieces of conventional SRT syntax that we rely upon. Particularly, if a subtitle introduces a new speaker, the block is preceded by >>, so when Lester Holt began speaking at the beginning of the first debate, the SRT block looked something like:
1
00:00:000 --> 00:06:454
>>LESTER HOLT: I'm Lester Holt anchor of
NBC nightly news...
We use these new speaker indicators to break up the SRT chunks into paragraphs. Since the SRT chunks are not broken into paragraphs or sentences or any predictable grammatical structure, the only thing we can rely upon is the introduction of a new speaker. So if a new SRT chunk does not begin with a speaker, we append the new chunk to the end of the preceding paragraph.
Once we’ve built our paragraphs, we append them to the Google Doc using Google Apps Scripts’ Document Service. This allows us to append to the document easily.
Remember, however, that we have fact checkers working live in the document. So let’s say, for example, that the last SRT chunk we received ended halfway through Donald Trump’s answer to a question on jobs. The next time we receive an SRT chunk, we want to append the rest of Trump’s answer to the same paragraph. But what if someone has already started fact checking that paragraph?
You’re starting to see some of the limitations of this rig. We can’t have fact checkers work on the last paragraph of the transcript. We handle this by automatically adding a horizontal rule and a line of text that says “DO NOT WRITE BELOW THIS LINE,” a small piece of UI that reminds fact checkers. It’s not a huge deal, since new transcript comes in every minute, but it is important to note that this isn’t a perfect system. But letting our fact checkers work inside a Google Doc has been worth the downsides.
We also built a good amount of tooling around the development of Google Apps Scripts. Google would very much like you to work inside of their editor on the web, but through the Google Drive API, we were able to get our scripts inside of our own dev environment and version control, and upload them to Google Drive for execution.
Google Apps Scripts also provides an execution API, which allows you to fire a function inside of a Google Apps Script from a third party, such as a Fabric command. This allows us to set configuration on the Google Apps Script project, such as telling the script what the ID of the Google Doc we want to append to is.
Unfortunately, the execution API cannot fire functions that create triggers (the script’s version of a cron job), so actually starting the trigger is a manual process that requires going into the Google Apps Script on Google Drive.
Google Apps Scripts comes with built-in logging, but it is not very good. Instead, we used our own logging system heavily based on BetterLog by Peter Herrman, which sends messages to a Google Spreadsheet.
The Google Doc
Again, as the transcript is appended to the document, we have fact checkers adding annotations within the same document, as well as editors cleaning up and copyediting the transcript itself. This creates a potentially chaotic environment in the document, and one that could lead to serious errors or incomplete statements from our reporters appearing on the page.
The secret ingredient to the Google Doc workflow is Suggesting mode. By default, anyone we share the document with can only work in Suggesting mode, with the exception of the editors who need the ability to edit and approve suggestions. Working in Suggesting mode means that fact checkers can construct their entire annotation, and our editors can fully edit them, before any of it reaches the exported HTML of the document.
Using Conventions to Create Structure
Because Google Docs is essentially a word processor, it’s a challenge to create the basic structure required to show which candidate statements we are fact checking, as well as to distinguish annotations from the transcript text itself.
Let’s look at an example from our first debate document:
DONALD TRUMP: Excuse me. I will bring back jobs. You can’t bring back jobs.
HILLARY CLINTON: Well, actually, I have thought about this quite a bit.
DONALD TRUMP: Yeah for thirty years.
HILLARY CLINTON: Well, not quite that long. I think my husband did a pretty good job in the 1990s. I think a lot about what worked and how we can make it work again.
DONALD TRUMP: Well, he approved NAFTA. He approved NAFTA, which is the single worst trade deal ever approved in this country.
HILLARY CLINTON:…a balanced budget, and incomes went up for everybody. Manufacturing jobs went up also in the 1990s, if we’re actually going to look at the facts.
NPR: sh-jobs-year For comparison: jobs per year was strongest under Bill Clinton (2.8 million), followed by Carter (2.6 million), Reagan (2 million), Obama (1.3 million as of January), H.W. Bush (659,000), and W. Bush (160,000).
And here’s the same section as presented in our app:

We add two things to the document to handle annotations. First, we bold the text we want highlighted in the transcript. This is simple enough. The next part—unique IDs for each annotation—is harder.
Our annotations are always prefixed with NPR: in the same way that HILLARY CLINTON: and DONALD TRUMP: appear in the transcript. Following the prefix, we give every annotation a slug. The first part of the slug is the author’s initials. Then, any number of words can be appended to the slug, we just need the slug to be unique. In the client-side app, we rely upon unique IDs for each annotation for a number of things including triggering animations and tracking read fact checks in our analytics. This will allow us to build unique shareable URLs for each annotation in the future.
Unfortunately, because an annotation can be added to any part of the document at any time, we cannot build IDs sequentially. We also cannot build IDs based on the text of the annotation because the annotations may get edited further after they first appear on the site. The only way to guarantee we maintain the same ID for any annotation is to hard-code the annotation within the Google Doc. The obvious risk here is that duplicate IDs are created, so we check for that when we parse on the server later.
The Server
Our server does three things: it uses the Google Drive API to download our transcript Google Doc as HTML, runs that HTML through copydoc and a custom parser to construct the HTML we use on the client side, and deploys that HTML to Amazon S3. This is all set up as a Flask app controlled by a daemon running on Ubuntu through upstart.
The custom parser handles a few specific cases:
- Takes speaker attributions (i.e.
DONALD TRUMP:), removes them from the paragraph and recreates them as<h4>tags above the paragraph. - Replaces
<strong>tags with custom<span>tags that handle our highlighted text. - Finds annotations and creates our custom DOM structure for annotations. This includes matching the author’s initials in the slug to a dictionary that contains their full name, job title, and a link to their photo.
This is all handled by parsing the HTML through Beautiful Soup. Transforming the annotations is the most complicated case. Here, we have to identify annotations based on the NPR: slug syntax explained in the Google Doc section. Then, in the function below we recreate the contents of the annotation and wrap it inside of the markup structure we want our annotations to have on the client.
extract_fact_metadata_regex = re.compile(ur'^\s*(<.*?>)?NPR\s*:\s*(([A-Za-z0-9]{2,3})-[A-Za-z0-9-]+):?\W(.*)', re.UNICODE)
FACT_CHECK_TPL = '''
<div class="annotation" id="%(slug)s">
%(fact_check_text)s
<div class="annotation-header">
<img class="%(annotation_label_class)s" src="%(author_img)s"></img>
<div class="annotation-byline">
<a class="byline-name" href="%(author_page)s">%(author_name)s</a>
<span class="byline-role">%(author_role)s</span>
</div>
</div>
</div>
'''
PARAGRAPH_TPL = '<p>%s</p>'
def transform_fact_check(paragraphs, doc):
"""
adds markup to each fact check
"""
# This will wrap all the fact check paragraphs
fact_check_wrapper = doc.soup.new_tag('div')
fact_check_wrapper['class'] = 'annotations-wrapper'
for paragraph in paragraphs:
# We need to recreate the contents since copyDoc
# is stripping the spans but leaving the child structure untouched
combined_contents = ''
for content in paragraph.contents:
combined_contents += unicode(content)
m = extract_fact_metadata_regex.match(combined_contents)
if m:
slug = m.group(2).lower()
annotation_label_class = 'annotation-label'
author = m.group(3).lower()
if m.group(1):
clean_text = m.group(1) + m.group(4)
else:
clean_text = m.group(4)
# Grab info from dictionary
try:
author_name = app_config.FACT_CHECKERS[author]['name']
author_role = app_config.FACT_CHECKERS[author]['role']
author_page = app_config.FACT_CHECKERS[author]['page']
author_img = app_config.FACT_CHECKERS[author]['img']
except KeyError:
logger.warning('did not find author in app_config %s' % author)
author_name = 'NPR Staff'
author_role = 'NPR'
author_page = 'http://www.npr.org/'
author_img = ''
# Handle author images, which some authors may not have
if author_img == '':
annotation_label_class += ' no-img'
else:
logger.error("ERROR: Unexpected metadata format %s" % combined_contents)
return None
new_paragraph = BeautifulSoup(PARAGRAPH_TPL % (clean_text), "html.parser")
fact_check_wrapper.append(new_paragraph)
fact_check_markup = FACT_CHECK_TPL % {
'slug': slug,
'annotation_label_class': annotation_label_class,
'author_page': author_page,
'author_name': author_name,
'author_role': author_role,
'author_img': author_img,
'fact_check_text': fact_check_wrapper}
markup = BeautifulSoup(fact_check_markup, "html.parser")
return markup
Once we have run the entire transcript through our parser, the HTML string returned through Beautiful Soup is rendered to an HTML file through a Flask route. We bake that route to a flat HTML file and deploy it to S3, where our client app will request it and display it to the user.
The Client-Side App
Our client-side app handles two main things:
- Requesting the flat, parsed HTML file that the server deployed to S3, parsing it into the virtual DOM, and patching the DOM with the necessary changes.
- Managing the state of each annotation—that is, whether a user has seen or read a particular annotation.
I’m a framework nihilist, so rather than use a heavy framework with all kinds of assumptions about code structure like React, we are using virtual-dom with its bindings for hyperscript to construct virtual DOM elements and handle the diffing needed to apply only the necessary changes to the DOM.
Our app has three main parts: the header, the transcript, and the footer. Our initial HTML page is quite simple:
<html>
<head>
<!-- CSS and meta tags and whatnot -->
</head>
<body>
<div class="header-wrapper"></div>
<div class="transcript-wrapper"></div>
<div class="footer-wrapper"></div>
</body>
</html>
On page load, we render our initial DOM objects for the header, transcript, and footer. We do that by first constructing each piece as a virtual DOM element in hyperscript, rendering it to a real DOM element, and then appending the real DOM element to the page.
const initUI = function() {
const headerData = {
'updated': moment().format('hh:mm a') + ' EDT ',
'numAnnotations': 0
}
headervDOM = renderHeadervDOM(headerData);
headerDOM = createElement(headervDOM);
headerWrapper.appendChild(headerDOM);
transcriptvDOM = renderInitialTranscriptvDOM();
transcriptDOM = createElement(transcriptvDOM);
transcriptWrapper.appendChild(transcriptDOM);
const footerData = {
'updated': moment().format('hh:mm a') + ' EDT ',
'newAnnotations': 0
}
footervDOM = renderFootervDOM(footerData);
footerDOM = createElement(footervDOM);
footerWrapper.appendChild(footerDOM);
}
To see virtual DOM construction in action, here is how we render the footer:
const renderFootervDOM = function(data) {
const annoStr = data.newAnnotations === 1 ? 'annotation' : 'annotations';
const annoNum = data.newAnnotations === 0 ? 'no' : data.newAnnotations;
return h('div.footer', [
h('div.update-wrapper', [
h('p.update-notice', [
'While you were reading, we added ',
h('span.update-number', annoNum + ' new ' + annoStr + '.'),
]),
h('p.update-info', 'To make new annotations easier to spot, we\'ve marked them in yellow. Scroll back up to see what you\'ve missed.')
]),
h('div.footer-nav', [
h('span.last-updated', ['Last updated: ' + data.updated]),
h('a.jump-to-top', {
href: '#'
}, 'Back to top')
])
])
};
With the UI initialized, we can request our transcript file. We’re using superagent and setting an “If-Modified-Since” header on the request to get new data only when it is available. When we request the transcript, we receive the HTML as a string in the response. And here’s where the magic happens.
New to me was JavaScript’s native DOM parser, which can take an HTML string and turn it into a DOM node. We use that to turn our response into a DOM node and parse it to our needs.
It’s not as simple as just diffing the changes to the DOM with the current DOM on the page. This is because we animate annotations that a user has not read yet, which means we have to maintain state on the client. We handle those animations through CSS classes. So, when the entire transcript is parsed, we need to determine which annotations need to have a class of unread and which annotations do not.
Consider this function:
const buildTranscriptvDOM = function(transcript) {
const children = transcript.children;
const childrenArray = Array.prototype.slice.call(children);
return h('div', {
className: transcript.className
}, [
childrenArray.map(child => renderChild(child))
]);
function renderChild(child) {
let element = null;
if (child.tagName === 'DIV') {
if (child.classList.contains('annotation')){
element = renderAnnotation(child);
}
} else {
element = virtualize(child);
}
return element;
}
function renderAnnotation(child) {
const id = child.getAttribute('id');
if (readFactChecks.indexOf(id) === -1){
child.classList.add('unread');
}
if (seenFactChecks.indexOf(id) === -1){
child.classList.add('offscreen');
}
return h('div', {
id: child.getAttribute('id'),
className: child.className
},[
virtualize(child.querySelector('.annotations-wrapper')),
virtualize(child.querySelector('.annotation-header'))
])
}
}
A few things to note: the virtualize() function comes from vdom-virtualize, which transforms a DOM node into a virtual DOM node. This is necessary so we can apply virtual-dom’s diffing engine. And we are maintaining global lists of fact checks a user has read (had on screen for about a second and a half) as well as fact checks a user has seen at all.
This function takes the transcript DOM node, finds annotations, and decides whether or not they have been read or seen by the user yet, and applies the necessary classes. It also transforms the entire DOM node into a virtual DOM node.
So, yes, we are taking an HTML string from an external file, turning it into a DOM element, then virtualizing it (after some reconstruction), then unvirtualizing it and applying to the DOM. It’s roundabout. But it works. (If I had to do it again, I might look at morphdom instead.)
Let’s step back. We have requested an HTML file that contains the parsed transcript from the Google Doc. Once we have a response from that file, we update the transcript on the page. That high-level function looks like this, including a call to our function above:
const updateTranscript = function(data) {
const domNode = parser.parseFromString(data, 'text/html');
const transcript = domNode.querySelector('.transcript');
const newTranscriptvDOM = buildTranscriptvDOM(transcript);
const patches = diff(transcriptvDOM, newTranscriptvDOM);
transcriptDOM = patch(transcriptDOM, patches);
transcriptvDOM = newTranscriptvDOM;
registerTrackers();
}
There’s a couple pieces of virtual-dom magic here, notably the diff() and patch() functions. diff() takes two virtual DOM nodes and finds the differences between them, much like a git diff, and returns patches. patch() takes those patches and applies them to a real DOM node.
Based on our updated transcript DOM, we update our header and footer based on, basically, the lengths of document.querySelectorAll() calls. We use the same virtual DOM diffing and patching logic as above.
Embedding
The final piece of this monstrosity is making the whole thing work inside an <iframe>. We have pym.js, our JavaScript library for embedding iframes responsively, which gets us most of the way there. But much of the functionality of the transcript—controlling when an annotation animates and when it fades to gray—hinges on its visibility in the viewport. Iframes, especially cross-domain iframes in our case, make this more complicated.
Detecting the visibility of an element inside an iframe from the parent when the iframes are not on the same domain is not possible. Similarly, detecting the scroll position of a user from inside the child iframe is not possible. However, Pym gives us the ability to send messages cross-domain, so we can leverage that functionality to complete a handshake of sorts. Here’s how it works.
When we identify a new annotation in our virtual DOM-diffing, we send a message to the parent asking it to register a visibility tracker for that annotation. Our tracker listens for scroll events and checks to see if its annotation is in the viewport. It does this by sending a message through Pym to the child. When the child receives the message, it finds the size of the annotation and its position relative to the iframe with getBoundingClientRect(). Then, it returns that rect to the parent. With that information, the parent calculates the user’s scroll position and the annotation’s true position on the page by offsetting the child’s results with the iframe’s current position on the page. With all this information, it can determine if the annotation is visible. Phew!
Here’s some simplified code to give an example.
On the parent:
var VisibilityTracker = function(iframe, id) {
var WAIT_TO_ENSURE_SCROLLING_IS_DONE = 40;
function isElementInViewport(rect) {
var iframeRect = iframe.getBoundingClientRect();
var vWidth = window.innerWidth || document.documentElement.clientWidth;
var vHeight = window.innerHeight || document.documentElement.clientHeight;
var verticalScroll = vHeight - iframeRect.top;
var bottomBound = rect.bottom + vHeight;
// Track partial visibility.
var leftSideIsToRightOfWindow = rect.left > vWidth;
var rightSideIsToLeftOfWindow = rect.right < 0;
var topIsBelowVisibleWindow = rect.top > verticalScroll;
var bottomIsAboveVisibleWindow = verticalScroll > bottomBound || rect.bottom > verticalScroll;
if (leftSideIsToRightOfWindow ||
rightSideIsToLeftOfWindow ||
topIsBelowVisibleWindow ||
bottomIsAboveVisibleWindow) {
return false;
}
return true;
}
function checkIfVisible(rect) {
var newVisibility = isElementInViewport(rect);
if (!isVisible && newVisibility) {
pymParent.sendMessage('fact-check-visible', id);
}
isVisible = newVisibility;
return newVisibility;
}
addEventListener('scroll', handler, false);
pymParent.onMessage(id + '-rect-return', function(rect) {
checkIfVisible(rect);
});
function sendRectRequest() {
pymParent.sendMessage('request-client-rect', id);
}
var handler = throttle(sendRectRequest, WAIT_TO_ENSURE_SCROLLING_IS_DONE);
// Initialize
sendRectRequest();
}
// register the tracker
pymParent.onMessage('new-fact-check', function(id) {
var iframe = document.getElementById('transcript-embed');
var tracker = new VisibilityTracker(iframe, id);
trackers[id] = tracker;
});
And on the child:
let trackedFactChecks = [ ];
pymChild.onMessage('fact-check-visible', onFactCheckVisible);
pymChild.onMessage('request-client-rect', onRectRequest);
const onFactCheckVisible = function(id) {
const factCheck = document.getElementById(id);
factCheck.classList.remove('offscreen');
if (seenFactChecks.indexOf(id) == -1) {
seenFactChecks.push(id);
updateFooter();
}
}
const onRectRequest = function(id) {
const factCheck = document.getElementById(id);
const rect = factCheck.getBoundingClientRect();
pymChild.sendMessage(id + '-rect-return', rect);
}
// this function fires when we receive new transcript
const registerTrackers = function() {
const factChecks = document.querySelectorAll('.annotation');
let currentFactChecks = [ ];
[ ].forEach.call(factChecks, function(check) {
const id = check.getAttribute('id');
currentFactChecks.push(id);
if (trackedFactChecks.indexOf(id) === -1) {
trackedFactChecks.push(id);
pymChild.sendMessage('new-fact-check', id);
check.classList.add('new');
setTimeout(function() {
check.classList.remove('new')
}, 200);
// this uses pym to update the iframe height
check.addEventListener('transitionend', updateIFrame);
}
});
}
This project also gave us an opportunity to add a new feature to Pym. We wanted the ability to scroll the page to certain elements within the iframe, so we added two shortcuts that make this possible: scrollParentToChildEl and scrollParentToChildPos. This lets you tell the parent to scroll to a child element (referenced by its ID) or a pixel position relative to the top of the child.
The Recap
I’ve covered the technical side of our transcripts and fact checking, but I haven’t even approached the design decisions we made and why we made them—topics my colleagues Katie Park and Wes Lindamood can dig into.
Just to go over all the things here, I’ll bring back David’s tweet.
transcription service ←→ google app script → google doc (+18 factcheckers) ←→ server → s3 → embedded widget
This is a highly complicated piece of technology, but ultimately, we designed it so we could get a dozen-plus fact checkers doing what they do best, in an editing environment that makes sense to them. And the results showed. The first debate led to NPR’s biggest traffic day ever, and this is the most successful piece—in terms of traffic—the Visuals team has ever built.
Credits
-
 Tyler Fisher
Tyler Fisher
Tyler Fisher is a senior news apps developer at POLITICO. Previously, he worked on the NPR Visuals Team and the Northwestern University Knight Lab.


