Learning:
Everything You Ever Wanted to Know About Elections Scraping
The Fine Art of Anticipating and Catching Errors in Deeply Weird Data
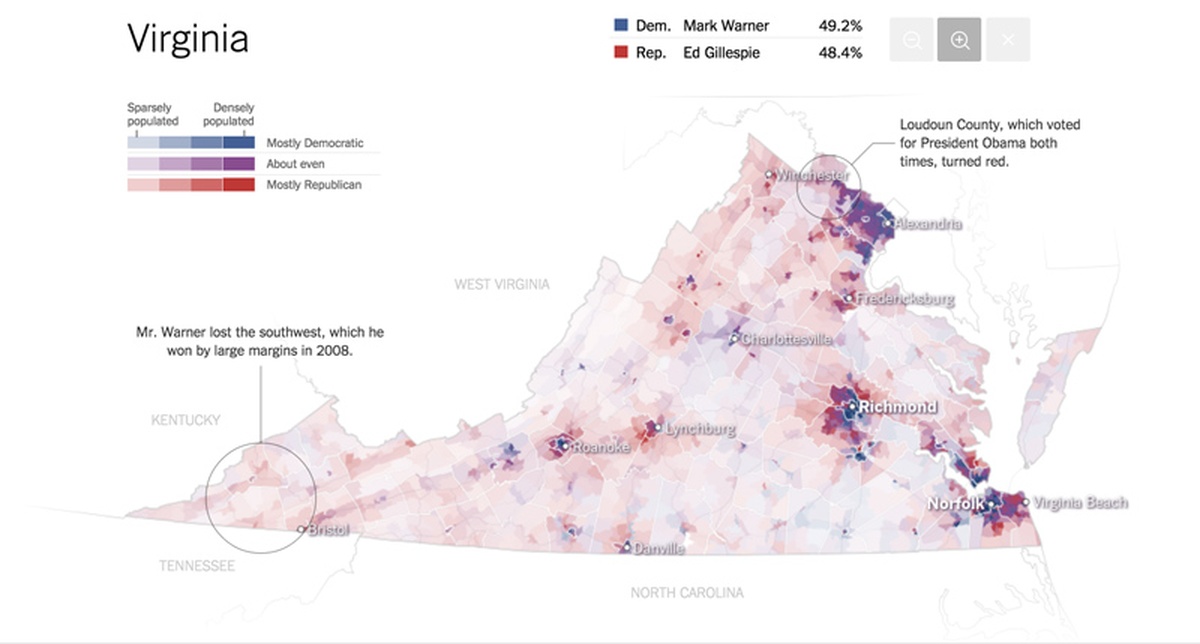
From the New York Times’ “The Most Detailed Maps You’ll See From the Midterm Elections” by Amanda Cox, Mike Bostock, Derek Watkins, and Shan Carter.
Comprehensive election data is nearly impossible to obtain quickly, accurately, and for free. The typical solution is to buy the data from an organization like the AP, which charges thousands—even hundreds of thousands—of dollars for the feed that powers the maps, charts, and analysis seen on your favorite news site. AP gathers this data in a reliable but old-fashioned way, with people on the ground. These people send the AP a constantly shifting tally as the votes are counted up, which the AP publishes in detail down to the county level.
What’s Missing?
The important thing to remember about the AP data is what it doesn’t include. Counties aren’t the most granular data available. Data exists down to the precinct level, often your actual polling place, and many states report results that thoroughly, by precinct, on election night or soon after.
Some of the states that report precinct-level data pay fees in the six figures for a service that manages their data reporting, called Clarity Election Night Reporting. Others use homegrown publication systems, like an FTP server hosting a strangely-delimited series of files (which is, honestly, not much different than the AP’s own solution), or simple HTML tables on little-used state websites.
Since most don’t use the same publication system, they certainly don’t use the same reporting format. Which makes gathering and collating that data a pain in the ass. And that’s exactly what we did for the 2014 midterm elections.
Do Try This at Home
If you’re a local or regional news org, it may be possible to use only your state’s own (free!) data for election reporting by using some of the same techniques we did.
Thar be dragons in this data. Don’t call us St. George, but we’re going to describe these and share with you how we defeated them. Processing the data isn’t necessarily the hard part, though it is also a battle; the dragon is anticipating errors and catching errors. This isn’t a problem unique to elections data. It applies to data journalism, software engineering generally and… umm… starting wars based on questionable evidence. As that pioneering data journalist Donald Rumsfeld put it, “there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns—the ones we don’t know we don’t know.” Just as Rumsfeld warned, it’s the unknown unknowns, the errors, that you’ve got to worry about more than the data cleaning.
Data Cleaning: Nice to Meet You, Senators Perdue(R) and Perdue (R)!
There are the data problems you’d expect: As we said, state boards of elections all publish in different formats and in different ways. States that use Clarity report their data in three JSON files per county that you have to join between in order to get the candidate, precinct, and race names, as well to find out whether the precinct is done reporting yet. Minnesota and North Carolina use a dialect of CSV, but Minnesota also requires you to join tables together to get identifiable names, and North Carolina is a giant zip file. Louisiana publishes a massive XML file. Alaska? Let’s not even talk about what Alaska thinks a CSV file should look like.
But if you could just come up with a Rosetta Stone to standardize that data format, you’d be golden, right? Wrong.
It shouldn’t surprise you that candidate’s names are spelled and formatted differently on the ballots in different states—maybe Barack H. Obama here and Obama, Barack there. But even within states, the diversity of spellings can reach levels rivalled only by endangered wildflowers.
Georgia, which uses the commercial service Clarity, is what we have in mind here: they managed to spell their now-senator-elect’s name four different ways in their results: “DAVID A. PERDUE”, “DAVID A. PERDUE (R)”, “DAVID A. PERDUE(R)”, “DAVID PERDUE (R)”.
And bless Iowa’s heart, but their CSV includes trailing spaces at the end of everyone’s name. Why? I don’t know. So “Bob Quast” of the Bob Quast for Term Limits party didn’t get any votes, but “Bob Quast ” did.
Virginia couldn’t keep from inventing new precincts to put into their data. After 11 p.m. on election night, they were still renaming precincts like “###Provisional” to “###Provisional 05” in Southampton County.
If you’re too old-school for all this almost-mechanical data-cleaning, don’t worry, there’s phone calls to be made too. Telephone-assisted reporting.
When a result shows up for the “Chanhassan P-1A” precinct in Minnesota’s Carver County, for example, that’s the complete count for that precinct. Clarity systems report a status—whether the precinct hasn’t started reporting, is done, or if more votes are expected. Determining whether a precinct has started yet isn’t as simple as noting whether all the counts are zero. Especially in low turnout elections like the midterms, a precinct that really recorded zero votes the whole day isn’t impossible.
But, in North Carolina, there’s no telling. An official in the State Board of Elections told me that results, when reported, should be complete, but “it can happen” that the numbers are changed afterwards: some counties have multiple types of voting machines whose data could be uploaded separately, and “transfer” votes from folks who moved, but didn’t change their registration, could be recorded at the county board of elections but later added to the correct precincts totals. All this informs our graphics and analysis and isn’t clear from the “raw data.”
We had to tackle these problems both across states—agreeing on a format to dump everything to, creating shared methods to output and upload the data, etc. We also had to tackle these problems within each state.
Architecture
We created a flotilla of tiny scrapers to attack each state. They each were scheduled to run every three to ten minutes with a Mac/Linux tool called “cron” for each state once its polls closed, and depending on how often the state promised to update their data. Each state parser existed to deal with the peculiarity of that state’s election system: where the file was, how it was formatted, what variations of a candidate’s name existed. The implementation of how to deal with output, uploading, canonicalizing the names, etc. were all offloaded shared functions.
Where Edward Tufte likes to talk about “small multiples” of information graphics, we created small multiples of crappy node.js parsers. Just like little maps of the extent of drought in the U.S. each year help you understand its spread, the nine scrapers we wrote helped us understand our code. They each used a roughly similar format of grabbing the input data, stashing it locally, processing it, and writing it. While this is good software engineering practice, it was especially important for a rushed and time-sensitive two-person project in which we both needed to be able to understand and fix each other’s code and be able to make flotilla-wide modifications.
It was these flotilla-wide shared functions, often made at the last minute, that made the project feasible. Shared functions transformed lists of candidate and race name variants (remember all the Davids Perdue?) into a single output. Another took charge of adding a timestamp to our output JSON, and writing it both locally and to Amazon S3 as a timestamped file, for example NC-18.42.16.json for posterity, and as NC-latest.json for immediate use.
Managing the Unknown Unknowns
Processing XML, JSON, or CSVs is easy though, you’re thinking. You’re totally right. It is easy—if you can build for a scenario that mimics real life. We had some sort of base data format for every state: a static dataset representing the most recent election, or a file filled with zeros, or test data for the next election. So, just as St. George had only a lance to fight the dragon, rather than the bazooka he probably would have preferred, we didn’t have any way to test how the data was updated over the course of election night.
On election night, around 9 p.m. when results started to arrive in earnest, we realized how really bad our logging system was and wished we had built a better one. Each state’s parser printed a message when it started and when it finished. This is the exactly wrong way to approach logging the status of your scrapers. What were we going to do, watch for nine messages to keep track of which didn’t finish, indicating failure? Yes, that’s what Jeremy tried to do, and it didn’t work very well. He got bored quickly, and missed some bugs it took much too long to catch as the night went on.
A better approach, were we to re-engineer this system, would be to log only things that deserve attention, or modulate their volume with their urgency. We logged some minor exceptions in this way. For states that reported their files with some sort of timestamp (either on the file on an FTP server, or a timestamp on an HTML page), that state’s scraper would log if there was no new data. Sometimes, this was expected: maybe no new precincts had reported their data to the elections board in the three-to-ten minute interim. But, if it kept happening, that might mean something had gone wrong in the scraper, so a human had to watch to make sure this wasn’t happening often.
Our shared name canonicalizers, too, would log if they had found an unexpected name. This worked fairly well. Usually, that was a problem with the underlying data—either something sporadic, or Virginia deciding to rename a precinct again. These problems weren’t urgent, but did need some human attention to investigate.
Success of each state ought to have been logged quietly; just an “NC” in the console when NC was done. Failure has to be logged loudly: “NC has failed with error: SomeException”. Intermediate cases, like old data or unexpected results, need a human to be watching occasionally.
Platform
Node was a bad choice, by the way. We used a total of four web request libraries—you know, to do the one thing you’d think Node would be good for—to handle HTTP, HTTPS, HTTP requests that redirected, and FTP requests. We probably tried a good three more that didn’t work right. An upside is that version and package management is fairly well done, so installation is easy.
Despite the problems with Node, that easy installation came in handy when VPN issues made Jeremy switch to running three states’ scrapers on his personal laptop. Even though Alaska—which, by the way, reports only when it’s all done tabulating precinct results, around 5 a.m. EST—hadn’t reported yet, Jeremy took the scrapers, running on his work laptop, a Mac, home at 3:23 a.m. When he got home at 3:42 a.m. (after the quickest Midtown-to-Brooklyn trip ever), there was a problem: our cloud storage is accessible only within the Times’s network (for security reasons), so he had to be inside the VPN to upload results. But the VPN doesn’t let you access FTP resources. Uh oh. He had to create a new S3 bucket on his personal account to put the data from the FTP states in and run the scrapers for them on his personal laptop. Real fun, but he got to bed at 5 a.m.
Which is not so bad for election night, especially since we got the data, which our colleagues in graphics turned into some sweet maps.
Lessons Learned
What did we learn from this experience? Well, collecting election results is hard. One of our colleagues, Derek Willis, is involved in a project called Open Elections (funded by the Knight Foundation) specifically to help tackle this issue for historic data. There’s a good reason people pay money for nearly-live feeds.
Also, choose the subset of data you care about. We only cared about US Senate races. If we had been more broad in our scope, our data cleanup efforts would have had to be more thorough. It’s easier to only understand a small piece of the overall election night pie.
Further, when dealing with many wholly different data sources, devise ways to abstract away the repeating tasks. All of the sources will have to sanitize, output, and upload data in the same way. That leaves you to focus on the task of figuring out the peculiarities in each source. Also, if you go with small single-purpose data ingestors, errors are hopefully localized per data source. For example, if the scraper for Virginia had crashed, we would have still been receiving results for every other state.
But the best takeaway is that free, live, detailed results are actually possible in some states, and not only that—these free data are the most detailed sources you can get! You should call up your state board of elections and ask about how they report on election night. You just might be able to save your news organization a little money.
Credits
-
Jeremy B. Merrill
Jeremy B. Merrill is an programmer/journalist at the New York Times and a core developer on the Tabula project. He likes building things—especially tools for finding the story amid all the digital noise.
-
Ken Schwencke
Journalist and programmer. Building @propublica’s @electionland. Formerly @nytimes @latimes. Go Gators.



{kind=link}