Features:
Finding the Story in 150 Million Rows of Data
Al Jazeera America’s Joanna S. Kao on visualizing a hack’s implications
This article is cross-posted at Al Jazeera America’s Ajam Sessions blog.
On October 3, Adobe announced that a database containing millions of user account information had been hacked. At the time, Adobe said that only the security of 3 million user accounts had been breached. But a few weeks later, they said that 38 million active users had been affected. The following weekend, a dataset was published on several public forums containing 10 GB of Adobe user account data, presumably obtained by the Adobe hackers.
This story (you can find it here) began when I found out via Twitter that a friend of mine from school had obtained a copy and was providing copies to password researchers. The fact that there was allegedly 150 million rows of data and that data was on Adobe users was what first piqued my interest since I figured I was probably one of those users.
The Data
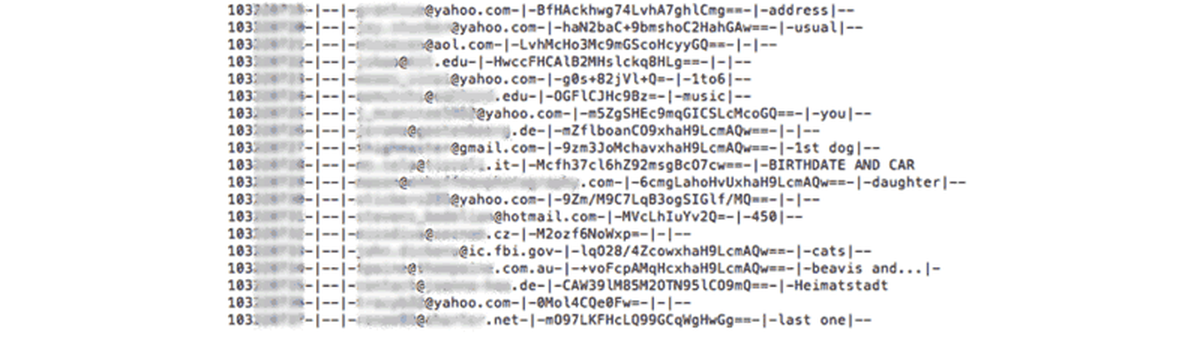
A challenge I ran into right off the bat was figuring out how to deal with the enormity of the data set. The compressed file, which contained one file of user data and another with Adobe personnel data, was 4.05 GB and the actual data file itself was 9.94 GB.
If you’ve ever wanted a reason for learning how to code and being savvy with command-line tools, here’s one—try to make sense of 150 million rows of data without it. Normal text editors don’t load 150 million lines, and they definitely won’t go into Google Refine (Google Refine estimated an 85 hour upload time before crashing).
Parsing the Data
The second challenge I ran into was parsing the data. My first instinct was to convert the dataset into a CSV or TSV so I could dump the data set into a database. But splitting the dataset wasn’t as easy as I first thought it would be.

Looking at the data, it looked like I could just split on ‘-|-’, but it turned out that ‘-|-’ and pretty much every delimiter could be found within the password hint field somewhere in the data set of 150 million rows. I ended up searching through the file for random weird strings that I could use as delimiters (I ended up using ‘*|||||*’, because yes, there are people who have ||||||| as password hints and some invalid email addresses with pipes in them). I ending up splitting most of it using a python script and fixing about a dozen rows by hand that didn’t seem to split correctly.
The Evolution of the Story
Once I got past the initial shock of seeing what was really in the data set and finding myself, friends and colleagues in the data set, I started to think about what kinds of stories could be gleaned. I started with the low-hanging fruit—some sort of visualization about people’s password hints. But after interviewing some password experts, I realized that the real story wasn’t about what types of passwords people used. The real story was about how easy it would be for people to crack large groups of same passwords based on password hints and how users with “bad passwords” could put even a “good password” in jeopardy. This fed back into a larger topic of online privacy and the security risks consumers take on each time they sign up for new services.
Designing the Graphics
The graphics on this article are fairly simple and straightforward. I wanted to show the data that was available and annotate it.

I found inspiration in this Fourier transform explainer by Stuart Riffle. I liked Riffle’s graphic because after explaining each part of the complicated Fourier transform equation, he could sum it all up using just the equation, one sentence and color coding.
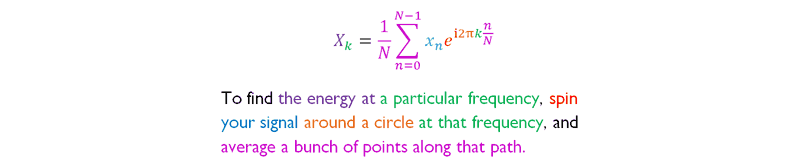
Creating the Game
I created a game to show people how easy it would be to crack an encrypted password by just aggregating the password hints of people who chose the same password.
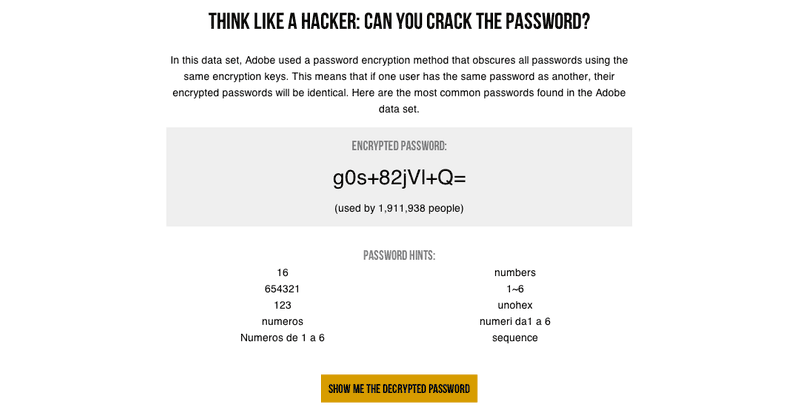
The game didn’t start out as a game. It actually started as a fairly confusing paragraph of text. After Lam and I worked on fixing up the paragraph, we decided that it still wasn’t good enough to illustrate the point. I chose to turn it into a game to drive home the point that it really is very simple to guess commonly used passwords just based on password hints.
Technical Tips
- Divide and conquer: 150+ million rows is unwieldy. For speed and to check my work, I split the 150+ million into 16 groups of 10 million each. Use a map-reduce job for running scripts (but do check your work and make sure you’re running it correctly).
- Test on small samples first: Test new scripts on small representative samples first. I took small chunks from different parts of my dataset (I took a small chunk from each chunk of 10 million) so I had a dataset with several thousand rows to test before running it on the entire dataset.
- Know how to use command-line tools. I’d start with man, grep, head, tail, sed, awk, cat, and less.
Lessons Learned
- It’s really easy to let articles about technical topics get filled with jargon. If you can’t take the jargon out, it is a very good indication that you don’t have a good grasp of the topic. So get a grasp of the topic, and then rewrite without all the jargon.
- Please don’t make your password ‘123456’, ‘password’ or reuse passwords. That’s just sad and you’re helping to ruin it for the rest of us.
Organizations
Credits
-
 Joanna S. Kao
Joanna S. Kao
Joanna S. Kao is a data visualisation journalist at the Financial Times. She was previously a multimedia reporter and interactive developer who covered veterans issues, immigration, and homelessness at Al Jazeera America. She creates immersive long form story templates, experiments with audio storytelling, and explores theater-related data in her spare time.


