Features:
Under the Hood of the Open Gender Tracker
Irene Ros and Nathan Matias break it down

Article gender by year for Global Voices, 2005-2012.
Earlier this week, we spoke with Irene Ros and J. Nathan Matias about the background and trajectory of their work on the Open Gender Tracker. Our Q&A follows their introduction to the project and its public appearances so far. —ed.
Many news organizations and editors want to share diverse voices with their readers. Opinion sections benefit from a variety of voices; journalists want to find the stories they’re missing. Many in online media want to represent issues fairly, to foster a healthy public sphere, and attract a diverse readership. Open Gender Tracker is an open source deployable service, funded by a Knight Foundation Prototype grant, which calculates the diversity breakdown of your content through various metrics such as the author’s gender.
We started Open Gender Tracker to develop automated gender analytics for the news: simply plug OGT into a newspaper’s API and get metrics that could be used for automated gender reports similar to Nathan’s analysis of UK news for the Guardian Datablog. Open Gender Tracker can currently estiamate the gender of who’s writing and who’s written about. We’re also doing experiments in quote extraction.
Since Gender Tracker adds analytics to your existing API, it offers all the reporting flexibility of the querying systems you’re already using. For example, we used the Boston Globe API to chart the writer and content gender for a year of Boston Globe reporting about cats (see above).
Although we started Open Gender Tracker to visualize gender for the news, the underlying architecture is a great starting point for any news content mashup project. Extending the system to compute new metrics about the data is built in to the core of GenderTracker. At the MIT Center for Civic Media, we’re talking about adding news geo-coding as well as social media analytics.
Project Origins
Q. How did you decide to build the Open Gender Tracker?
Irene Ros: I’ve always cared greatly about the future of journalism, as a news junkie myself. I started thinking about the inner workings of a newsroom while at IBM Research, and did a short project called NYTWrites that explored the diversity of topics a single journalist writes about. It allowed me to start many conversations with various organizations and I really haven’t looked back. Additionally, I care a lot about women’s voices, being a woman in the tech world, and so the two really came together in Open Gender Tracker.
What really allowed me to pursue this passion is working at an organization called Bocoup, an open web technology company. We all firmly believe and work towards making open source a viable alternative to closed-source software. With the support of my colleagues, I wanted to create a tool that isn’t just useful to one or two organizations, but one that will continue to grow and thrive in the open source ecosystem.
J. Nathan Matias: A year ago, to answer a question on Twitter, I charted byline and content gender across 20 years of a major international newspaper. I was shocked to see how flat the line was. I also learned about awesome groups like The Op Ed Project, the Global Media Monitoring Project, and VIDA, that collect data on gender in the news by hand.
As this issue turned into my Master’s thesis at the MIT Media Lab, I came to see that gender representation online is a much more complex issue than just bylines. OGT is one part of my broader work to expand how we measure and change gender representation across media ecosystems online. This spring, I’ll be releasing two more projects, in collaboration with Sophie Diehl, Sarah Szalavitz, and James Home.
How It Works
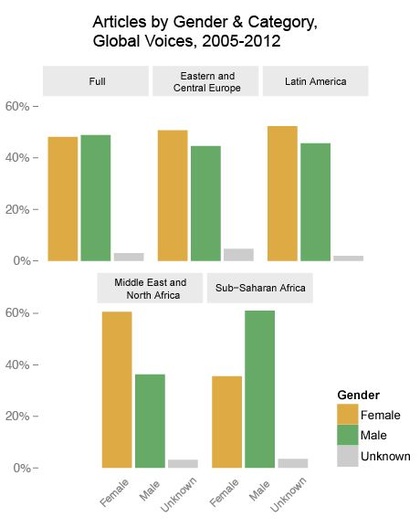
Gender analysis charts for Global Voices.
Q. Can you walk us through how the OGT analyzes gender in authorship and in coverage?
IR: OGT allows users to submit requests to process an article (or really any other text content) that is structured in a predictable way. Once it receives an article, it uses several techniques to calculate what it thinks the gender might be:
- First, it tries to guess the gender of the author by referencing a baby name dictionary. Adam Hyland did amazing work to create the most comprehensive open dataset on name gender. We’ll be writing about the Global Name Data archive soon, and you can follow its development here.
- Second, it looks at the pronouns used in the article and tries to determine whether they lean a certain direction.
JNM: Every news organization is different. Since OGT talks to real-time newsroom APIs as well as static content files, it’s very easy to slice the data in ways that are relevant. Using the Boston Globe’s API, we have been able to look at gender across sections, individual journalists, and even topics. My favourite queries right now are “beer” and “cats.”
Gender is a much more complex spectrum of identities and performances than just male and female. OGT offers speed and scale, but automated techniques aren’t very good at the nuances of personhood. Despite that, we believe that OGT can offer helpful real-time metrics to make visible overall trends in reporting.
Q. How did you build the OGT?
IR: We built it while doing our two case studies with Global Voices and the Boston Globe. Each study had very different requirements. Our Global Voices study focused on volunteer contributor participation and appeared in the Guardian Datablog. Our partnership with the Globe is a custom web application that they can use to conduct faceted browsing of gender data across their API. Since these projects were so different, we made OGT very flexible and extensible.
It’s fairly painless to set up and very easy to interface with using a messaging queue called Redis.
JNM: Under the hood, OGT is a ruby application (we use JRuby), which schedules batch jobs to process data from news APIs and static files. Jobs are queued using Redis. Text processing is done with Apache OpenNLP, but it really could be anything. Jobs don’t even have to be written in Ruby.
Outputs can be incredibly diverse. For our Global Voices study, we imported Open Gender Tracker into the R statistical software. The Boston Globe project is more interactive, storing results in MongoDB and serving them out to a Backbone.js app that visualizes the results.
Our new Global Name Data repository is another exciting part of this project. We have collected names from the US, UK, and Ireland and are hoping to add Chinese names from my colleague Huan Sun’s research on gender on Sina Weibo. We’re actively looking for name gender datasets from other cultures and would love to add more to this growing list.
Q. Did you encounter any interesting/weird challenges along the way?
IR: While working on the Global Voices analysis, we realized just how many of the names were not going to be in our primarily-English dictionaries. It was a really fascinating process of having to manually build these lists from a collection of very diverse names. We built in that functionality into OGT, realizing that news organizations from all over the world may encounter the same problem.
JNM: The remarkable diversity of Global Voices was a pleasant surprise. We almost got our analysis wrong. Global Voices publishes content across a cluster of Wordpress sites for different languages. In our very first attempt, we accidentally swapped translators for contributors in a few places. Thankfully, both Solana Larsen (managing editor) and Jeremy Clarke (Global Voices tech) graciously helped us correct our data analysis.
I would love to do a followup sometime on the contributions of Global Voices translators.
How to Use It
Q. What sort of data prep and input is required to analyze a news outlet’s coverage? What kind of setup process is involved?
IR: The main requirement OGT imposes is that a news organization converts their articles into a basic structured JSON format. Conversion is fairly minimal and doesn’t require any actual processing of the data—just reformatting. We’ve documented that format here.
The setup process itself is fairly painless. It requires JRuby, which we highly recommend using RVM for. Additionally, it relies on Redis, which is a really great key-value store. Once those services are configured, one just has to change their config.yaml file to point to the right locations and start the server. Our GitHub page has basic instructions, and we’ll be diving into more detailed setup instructions soon on our blog.
Q. Besides simple counts of bylines or mentions, what else can you help organizations track?
IR: One of the best parts of OGT is that you can very easily plug in new metrics. We’ve built the entire system around the idea that newsrooms and developers will want to contribute their own, so please do!
JNM: Audience metrics is an exciting next step for OGT, especially for news organizations that want to expand the reach of women’s voices. Lisa Evans and I used the Open News project Amo to add social media metrics to our Guardian Datablog post looking at audience attention and gender in a year of news. I’m also working on code to help with audience gender analytics and would love to find someone to help integrate it into Open Gender Tracker.
Adding new modules into OGT is very straightforward. Last weekend in London, a team at Rewired State’s Women of the World Hackday built software to detect the adjectives describing women in the news. I’m excited to learn from their code and possibly add a new module to OGT.
Modules don’t have to be about gender. Open Gender Tracker is a generic system for turning content into data and mashing it up with other data. My colleague Catherine’s utterly gorgeous news geocoding system, Mapping The Globe, was created before OGT, but now that she’s extending it to work for any publication, we’re thinking about turning it into an OGT module.
Where It’s Headed
Q. Where do you expect to take the project over the next few months?
IR: We are still working with the Boston Globe, and are very excited to see how OGT can be of use to them. As more and more organizations decide to try OGT, we hope to evolve it based on the needs and creativity other organizations bring to it.
JNM: Time permitting, I’m excited about audience analytics and personal trackers. Several journalists have asked me if I can create software that helps them monitor their use of sources and the language they use to describe men and women. I’m going to try to work on that in the small hours between my thesis chapters.
People
Organizations
Code
Credits
-
 Erin Kissane
Erin Kissane
Editor, Source, 2012-2018.
-
J. Nathan Matias
I study online safety & fairness among humans & AI. @PsychPrinceton @PrincetonCITP @medialab @CivicMIT Prev: @BKCharvard @MSFTResearch @Swiftkey @mini_stories
-
Irene Ros
Googler. Helping people find jobs. Opinions my own.


