Features:
What “Open” Really Means for 538, Vox, and The Upshot
The code and data they’ve released so far and what they’re planning next

A lot of media analysis has contrasted the work coming out of data-centric media startups/retools 538, Vox, and the Upshot, and a couple of recent-ish articles considered the code and data each outlet is publishing—or not publishing—as they get off the ground. The Guardian’s James Ball:
Doing original research on data is hard: it’s the core of scientific analysis, and that’s why academics have to go through peer-review to get their figures, methods and approaches double-checked. Journalism is meant to be about transparency, and so should hold itself to this standard—at the very least.
This standard is especially true for data-driven journalism, but, sadly, it’s not always lived up to: Nate Silver (for understandable reasons) won’t release how his model works, while FiveThirtyEight hasn’t released the figures or work behind some of their most high-profile articles. […] Counter-intuitively, old media is doing better at this than the startups: The Upshot has released the code driving its forecasting model, as well as the data on its launch inequality article.
And in Mother Jones, the Guardian’s former data editor Simon Rogers, now at Twitter, takes data journalists to task for failing to publish the data behind their articles.
Now that all three projects have been up for a few weeks, we took a closer look at the data, and especially the code, that each has released.
FiveThirtyEight: Iterating Toward Open
FiveThirtyEight came in for some specific and extremely thorough criticism in the form of a replication project and writeup from Brian Keegan, who attempted to replicate the data-crunching part of Walt Hickey’s Bechdel Test film economics article as the hook for a post arguing that data journalism should openly publish data sets and analyses. FiveThirtyEight responded by thanking Keegan and releasing their data set for the Bechdel article.
They’ve also released data (and sometimes code) for eight more articles—and, we note, persuaded Nate Silver to start making commits. [Correction: Andrei Scheinkman notes that their first data set went up in late March, before Keegan’s post—our initial wording suggested that they only began publishing data after the post.]
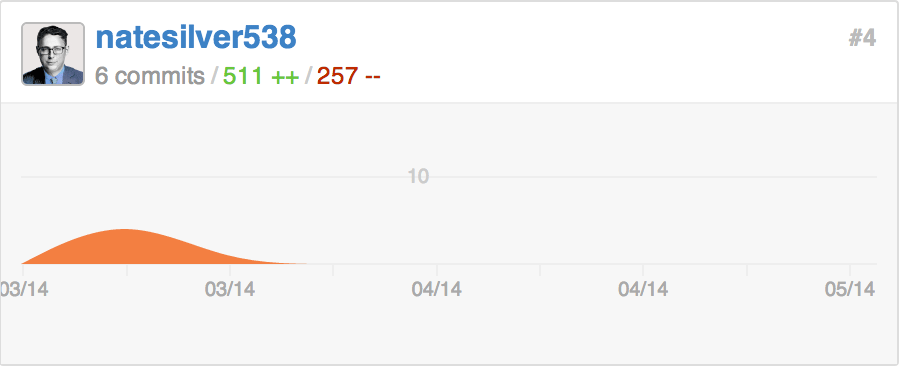
When we contacted him for comment, deputy editor Andrei Scheinkman told us that FiveThirtyEight considers it important to publish code and data to be transparent about methodology, but also because it encourages readers to check their work and because it opens up their journalism for other forms of reader collaboration, including “remix[ing] our work into their own analyses and visualizations”—collaborations FiveThirtyEight turns into roundups:
- A GIF-Guided Tour of Remixed FiveThirtyEight Data
- Happy Bob Ross Visualizations
- More Data Analysts Went Looking For the South And Midwest, And Here’s What They Found
Scheinkman told me “We’re going to start publishing more and more code and data. We’re currently working on getting everyone in the newsroom comfortable enough using GitHub, so they can publish the code and data behind their stories themselves.”
Vox: Sharing Knowledge Now, Code Coming Soon
from a recent Vox Product post on front-end performance testing
Vox Media has, more than most news organizations, positioned its publishing technology as a competitive advantage, so it’s not so surprising that Vox has been slow to release code and data sets—their public repos currently consist of forks of other projects.
In a conversation about his team’s plans for the immediate future, however, Chief Product Officer Trei Brundrett nodded toward some of Vox’s recent highly detailed tech-centric blog posts and said that his team plans to keep sharing what they’ve learned and what they’ve made, and to start releasing more code as well as documentation.
The Upshot: Publishing Backstory, Releasing What Makes Sense
The newest of the three sites, the New York Times’ internal startup the Upshot, launched only three weeks ago with a note from editor David Leonhardt that included a callout to open data and published code:
Perhaps most important, we want The Upshot to feel like a collaboration between journalists and readers. We will often publish the details behind our reporting—such as the data for our inequality project or the computer code for our Senate forecasting model—and we hope that readers will find angles we did not.
Those published details, for the launch-day income inequality piece, included an “about the data” post, a single-table supplement, and a lengthy backstory post from Leonhardt explaining his hunt for the elusive dataset behind the story and the intricate collaboration that produced the data his team eventually used.
On launch day, Amanda Cox, who co-created the Upshot’s Senate model, tweeted that the model’s code was already on GitHub:
Proud that Senate model code is on the internet. https://t.co/DvRs55bUbu May a thousand models bloom. cc @jshkatz
— Amanda Cox (@amandacox) April 22, 2014The Leo model’s repository includes the code required to run the analysis, a number of data sets, and a readme detailing other data sources:
Historical results from the Open Elections project, CQ Press Voting and Elections Collection, Dave Leip’s Atlas of U.S. Presidential Elections, and the Federal Election Commission.
Fund-raising data from the Federal Election Commission. Biographical data from Project Vote Smart and candidate websites.
Polls aggregated by Pollster, the Roper Center for Public Opinion Research, the U.S. Officials’ Job Approval Ratings project, Polling Report, Gallup, Talking Points Memo, The Argo Journal, Real Clear Politics and FiveThirtyEight.
We contacted Cox to ask about the Upshot’s criteria for publishing code and data, and she responded with her informal guidelines for releasing behind-the-scenes data and code:
My unofficial rule for everything is just “what makes sense.” I think posting is the responsible thing to do for something moderately complicated, like Leo, our Senate model. In the general case, we value transparency and humility. (I’m open to the idea that someone might be able to make Leo even better. It’s already been fun to watch Dan Nguyen write a little documentation for us.)
Fellow Upshotter Derek Willis added:
I’ve moved over some repositories from the Interactive News account because I use them in my reporting for The Upshot, so that seemed to make sense. As for data, I think you won’t see it all the time, but in cases where it would require a reader to piece things together or more than a few clicks to find, I think it’s probably worth publishing. That was my thinking for publishing the data behind two stories I’ve written.
News Sites, Old Practices
As Ball and Rogers and a lot of others have noted, journalists and journalist-developers at established news organizations have been releasing data and code for years—and their writeups and code breakdowns have populated Source since we launched. And although only the Upshot launched with day-one open code and none of the three projects routinely release data sets alongside each article, as ProPublica and the Guardian tend to do, it’s encouraging to see a chorus of voices pressing for transparency from this fresh crop of data-focused news organizations and projects. We look forward to featuring projects from all of them in the future.
People
Organizations
Code
Credits
-
 Erin Kissane
Erin Kissane
Editor, Source, 2012-2018.


