Features:
How We Made the (New) California Cookbook
The LA Times team behind the site breaks it down

At the Los Angeles Times, a design-editorial-programming team has resurrected the spirit of the beloved, out-of-print California Cookbook as a new website collecting hundreds of recipes from the Times Test Kitchen. In our Q&A, the project’s editor, designer, and lead programmer share their goals and challenges, and offer a peek at the site’s building blocks and planned future.
Editorial Planning
How did this project get started?
Megan Garvey (Assistant Managing Editor, Digital): The idea to collect our recipes online, in a searchable presentation, has been discussed for years. We believed that the work of our Test Kitchen was both unique and valuable. Ultimately, there were several reasons this recipes database moved to the front of the line for our relatively small news apps team:
- Our tradition of collecting L.A. Times recipes into cookbooks dates back to the early 1900s, so we were confident there was an audience.
- We tested this by creating recipe photo galleries that proved very popular.
- Then, last year, we took on the online presentation for food critic Jonathan Gold’s 101 Best Restaurants. Gold’s hotly anticipated reviews, coupled with a sharp responsive web design, attracted new digital subscribers, as well as more than 1 million page views. Prompted by that success, and the fun we had working on it, the core 101 team revisited the idea of a recipes database and decided to go for it.
Also, we just thought it would be really cool. We’ve all been cooking from it since Anthony got the first test version live.
Design
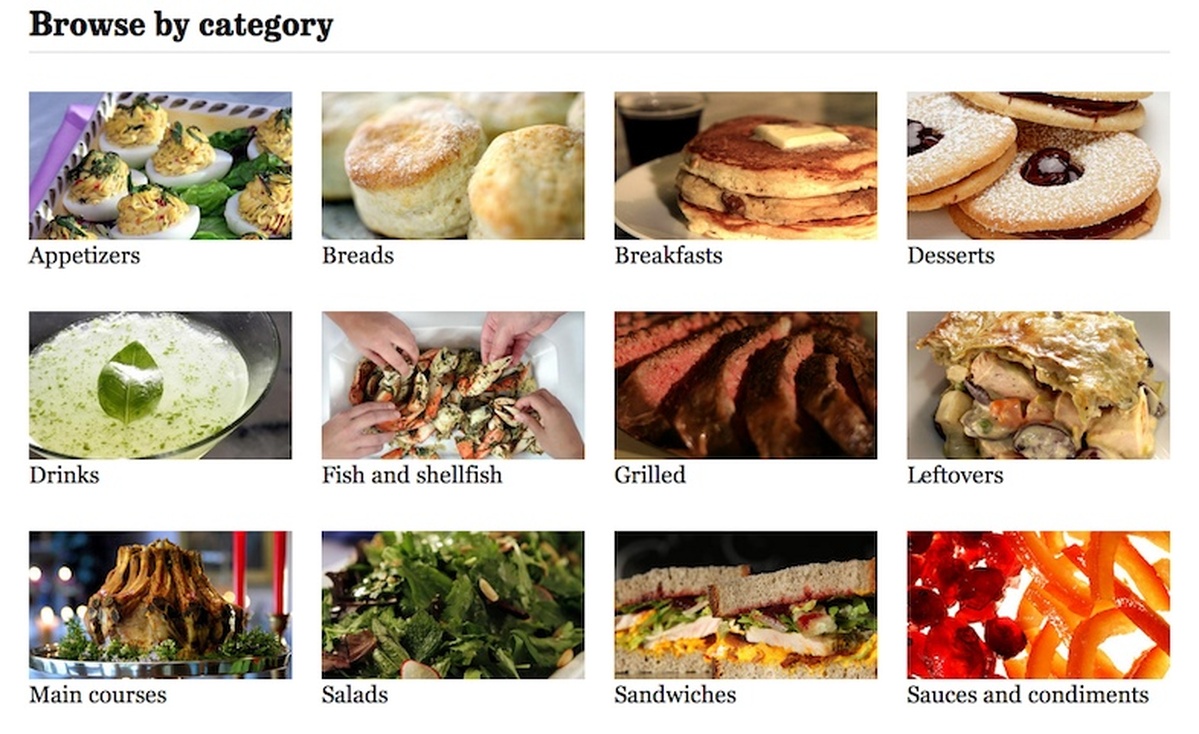
What was your design process like?
Lily Mihalik (Web Designer): We knew we had something unique: recipes that had been tested in-house, absolutely stunning photography and great writing. You eat with your eyes first, so from there it was pretty simple. We wanted something image-driven that gave readers many ways to graze their way through the site.

We started with the recipe page and a list of assets, focusing on imagery, utility, and stickiness (see the “Have You Tried?” sidebar). We settled on our favorite features—features we could develop in a limited time and in a responsive environment.
Because we chose to use a minimal nav bar to keep readers focused on the recipes site, organization was key. We needed categories, collections, and a search you could easily filter. And all these elements needed to be accessible from anywhere on the site. The goal was to create the digital equivalent of our out-of-print California Cookbook—a trusted source you want to return to time and again. But we knew it needed it to be modern, and that meant adding a way to save, rate, and share recipes with friends and family.
With the basics in place, other elements evolved organically. On the landing page, the “hero art” gallery provided another chance to inspire the wandering or waffling cook. All in all, it was a group effort: print and digital minds combined on all fronts to create, we hope, something that is as useful as it is stunning.
Data Wrangling
What kind of data were you looking at as you began? Was it all consistently structured?
Anthony Pesce (News Apps Developer): The most challenging (and fun) technical part of this project was taking an enormous amount of unstructured text from our archives and parsing out the components for each recipe. I decided to use a bit of natural language processing and machine learning to get the job done.
Our library keeps a digital archive of every story published in The Times going back to 1985. As a first run, we decided to focus on recipes from the year 2000 to present. Our librarians do a great job of tagging every story, so it was simple to pull all of the news stories, columns, etc., that contained a recipe. But beyond that, we had a pile of text that we needed to turn into a database—not easy. In addition, we knew we needed to find and match high-res photos with recipes. Again, the library archive made that possible because it stores the photo IDs with each record.

The single-recipe view
We had unstructured text that was virtually impossible to parse using more traditional methods you might employ–like regex and matching patterns and formatting. But we had (somewhat) well-defined fields we needed to extract: all recipes have titles, ingredients, steps, time to cook, servings, and nutrition. Most recipes have some description text, and sometimes they have a note. Natural language processing, with a bit of creative application and machine learning, can tag these components with a very high success rate.
Luckily, Python has a mature and robust natural language processing library called Natural Language Toolkit NLTK that comes packaged with machine learning algorithms built in, and has some pretty good documentation. To parse a recipe out of a news story, I first had to use NLTK to train a tagging engine and, second, write a script that would apply it appropriately for this application.
I started off manually parsing about 20 recipes, then played around with a tokenizing function that used the traditional “bag of words” approach as well as n-grams and part-of-speech tagging. Once I had the parser working, I built out a page in Django that loaded a random record from the database and attempted to parse it, paragraph by paragraph, and displayed the results. I then corrected the tags, saved the record, and periodically tweaked the tokenizer and parsing script. I was able to re-train the tagging engine along the way using the new records, and saw the accuracy improve dramatically.
Once I was happy with the parser, I set it loose on the database, and it returned close to 6,000 recipes. This got us about 95% of the way there, but humans still needed to review the output and prepare the recipes for publication. I built out a custom admin allowing a small group of people to compare the parsed recipe side-by-side with the original record and, if necessary, fix it.
We launched with 638 holiday-themed recipes, but we have roughly another 5,000 we plan to add to the site in phases.
Building Blocks & Technical Challenges
What’s the site built on?
Pesce: We recently released our project template on GitHub which does a pretty good job of demonstrating our basic stack, if you’re curious.
On the front end, it’s modified Bootstrap. The website is built with Django, using a PostgreSQL database, running on an Amazon EC2 server. We’re using Varnish as a front-end cache, and Memcached to cache some of the more expensive queries around the site. We use Fabric and Chef Solo to handle deployment.
Did you encounter any particularly interesting or complex challenges as you prepped the data and built the site?
Pesce: Other than parsing the recipes, the most challenging part of the project was how to handle the caching. This is the most user-intensive application the Data Desk has built, so I spent a lot of time researching options, and eventually decided on edge side includes to handle the user-specific content.
The basic premise is that the entire page is cached except for the user-specific parts, such as the login and saved recipes box, which are assembled and inserted for each request. Varnish can handle ESI processing by default, and I used Armstrong ESI for most of the Django integration.
I also learned the hard way that Varnish doesn’t merge in response headers from ESI includes—so in some cases users would not receive the session Set-Cookie headers, or would receive cached cookies from another user. I ultimately had to tweak the application to set the session cookies in JavaScript, inside the ESI include, and remove any Set-Cookie headers coming from a cached page in the Varnish configuration.
What’s Next
Can you tell us what you’re planning for the site’s future?
Pesce: We think a lot of the basic features are there, but we want to take some time to see how users are using the site and take feedback on what features people think we might be missing. We’re already folding new recipes directly into the database. We’re continuing to add older recipes from our archives and have thousands prepped on our staging site.
We’ve also talked about creating a place for the really vintage recipes, digging into both the beloved California Cookbook from the 1980s and the numerous L.A. Times’ cookbooks that predate it.
The next big advance will be building a more robust community by integrating comments, creating a video “cooking school,” adding a seasonal vegetable guide, and more.
Credits
-
Megan Garvey
Deputy managing editor, Los Angeles Times. Raising Frasier and Niles Crane replicas, ages 10 and 13. Endeavoring to make important things interesting.
-
 Erin Kissane
Erin Kissane
Editor, Source, 2012-2018.
-
 Lily Mihalik
Lily Mihalik
Lily Mihalik is the editor of news design at Politico. Lily is a proud alum of the Los Angeles Times Data Desk, The Berkeley School of Journalism, KPCC, Flipboard and KCAW in Sitka, Alaska.
-
Anthony Pesce
Data Journalist @latimes & @latdatadesk, co-chair of @latguild. Public key: https://t.co/pO61farAsH


