Features:
Free the Files API + Q&A with Al Shaw
ProPublica’s interactive data-analysis project gets an API and Al Shaw answers our development questions
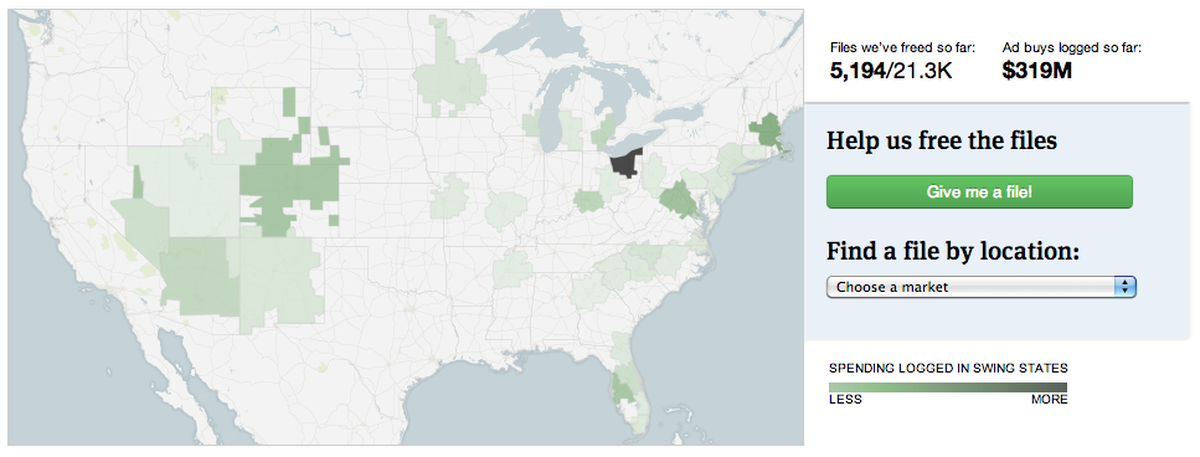
Free the Files nears $320M in logged ad buys.
A litle over two weeks ago, we launched our Free the Files project, in which ProPublica and our readers are working together to reveal political spending in 33 swing markets from ad buy documents TV stations file with the Federal Communications Commission. With over 5,000 files and $300 million freed by nearly 500 users, we’ve got plenty of data on political ad spending in the 2012 election. Today we’re opening up that data for developers in new API. Here are the API docs.
For now, the API will focus on four object types: markets, stations, committees and filings, and will only include files that have been “freed,” meaning that each data point in the filing has been reviewed and verified by more than one Free the Files participant. It also includes links to the original documents on the FCC’s site, and the versions we’ve uploaded to DocumentCloud. The API also includes FEC IDs when we have them, which can be used to link to PAC Track pages, or committee data in the New York Times Campaign Finance API.
The Free The Files API is the first ProPublica API based on dynamic user-contributed data, and we’re excited to see what developers can build with the every growing torrent of political spending. Check out the documentation and let us know what you build!
[Cross-posted to the ProPublica Nerd Blog.]
Source Q&A
At the launch of the Free the Files API, Al Shaw spoke with us about the context and challenges of building out their crowdsourced spending tracker.
Source: How did Free the Files emerge from your earlier Free the Files series, and accompanying campaign to get people to visit TV stations and collect ad spending files? Had you planned to build the present toolset all along, or was it something that you decided to do after the FCC Public Inspection site came online?
AS: We started building the FTF app back when we were sending people to TV stations to get files during the primaries. Back then, the original idea was based around a calendar of when campaigns and committees were spending on TV. When we realized that the data would be spotty because people weren’t going back to stations to get files week after week, we shelved the app until the FCC site came online. It was after we learned that the FCC data would be PDF-only (of highly variable quality), that our news apps fellow Jeremy Merrill, our engagement editor Amanda Zamora and I got to work on a crowdsourced repository of TV ad spending.
Source: What development challenges did the team encounter while building the Free the Files tools?
AS: The biggest challenges were working out how to assign files out, and how to confirm data that multiple people submitted when reviewing files. We started giving out files based on how “swingy” the market was, based on FiveThirtyEight rankings. That ended up skewing all of our data towards Ohio. Now we’ve made it a little more random, so the map will show actual spending trends, even if the data isn’t exhaustive yet. When you compare FTF to the Washington Post’s wonderful TV spending map, based on data from Kantar Media/CMAG, you can see we have a ways to go. But Free the Files is the first time it’s been possible to get close to what the private political ad spending databases have, which we’re really excited about.
We also weight slightly against giving files that look like they’re from campaigns, since we’re really trying to suss out third party “dark money” spending that may not be reported to the Federal Election Commission. Verifying data coming in was also tricky. We settled on a method where multiple people have to confirm each data point before the file can be considered “verified,” and it shows up in the app’s front end. This means that sometimes as many as ten or 15 people look at a file before it goes through, but the average is actually around three.
Source: Did you encounter anything unexpected once the crowd actually started doing crowdsourced file analysis? What kind of safeguards did you build in to help with human error (or mischief) on the part of file-freers?
AS: Besides the multiple-verification system, we haven’t had to do a whole lot of moderation. There is a user ban feature under the hood which isn’t getting much use. One thing we’ve experimented with was different rejection buttons. We actually now have three buttons that a user can click to throw out a file. One simply says “this is an invoice” because invoices look exactly like ad orders at many stations. Another one says “this is unreadable or not an ad buy,” and we recently added a third button for multiple contracts in a single filing, which was tripping up a lot of readers. We’re also going to be adding a feature soon to automatically suggest which committee bought the ad, which we’re scraping out of the FCC metadata. Another useful strategy was to create a companion Facebook group for FTF volunteers. Through that group, we have a constant open channel about what works and what doesn’t, so we can iterate on the file reviewing user interface.
Source:Do you think the leaderboard of most active file-readers has contributed to the project’s success?
AS: Totally. When we first started, I thought reviewing 100 files would keep me on the leaderboard forever. It turned out, I was buried on the first day, as people vied for higher placement. At the moment, you need to review over 566 filings to get on the all-time leaderboard, so people have been taking it pretty seriously.
Source: The next time you take on a project like this one, is there anything you’d do differently?
AS: Each news app we do is a bespoke artisanal creation, so there’s no real formula. Our Message Machine app, for example, is also crowdsourced, but the user experience is totally different. That app works almost completely through email, and we only ask users to fill out a form after they have forwarded a campaign message over, which works amazingly well. It all depends on the kind of data we’re trying to collect. The main concern is making it very easy (and rewarding) to participate.
Credits
-
 Erin Kissane
Erin Kissane
Editor, Source, 2012-2018.
-
Al Shaw
developer / designer / reporter at ProPublica • #bikenyc’er • PGP: https://t.co/Rm7puIOjUB


