Features:
How We Made @NailbiterBot
A new data-driven Twitterbot from start to finish

The first full round of March Madness is Christmas morning for college basketball fans: 2 days, 32 games, lots of upsets and late-game drama. Last week, on the first full day of the tournament, WNYC transportation reporter Jim O’Grady casually mentioned that he couldn’t keep tabs on all the action during the day. He wished he could get a text message whenever a game was coming down to the wire so he would know when to neglect his professional responsibilities and tune in for the end. I started kicking around the idea in my head a little, and after work my colleague Jenny Ye and I decided to take a break from writing weird JavaScript to write some more weird JavaScript. The result was @NailbiterBot, a humble Twitter bot that posts a tweet whenever an NCAA tournament game is close late in the second half.
DUKE (3) v. MERCER (14) is 63-63 with 2:33 left. http://t.co/xc9IiAdXnS
— Nailbiter Bot (@NailbiterBot) March 21, 2014Building the Bot
We needed something that constantly checks to see whether there’s a close game in progress, and if so, posts a tweet about it. The steps to building it would be something like:
- Find a source for live-ish game scores.
- Write a script that checks each game to see if it is in progress, near the end, and close.
- Extend the script so that it posts a tweet for each nailbiter identified (fortunately there are lots of modules/libraries that will do the Twitter API dirty work for you).
- Set that script to run every 30 seconds as a cronjob on a server somewhere.
Finding the Data
Deciding whether a game is close isn’t difficult once you have the current score and game clock, but getting that data is easier said than done. Most of the work for projects like these goes into finding accurate, up-to-the-minute data and reverse-engineering it into a usable format.
We started by going straight to the source, the NCAA.com scoreboard, and trying to scrape that page. It looks like this:
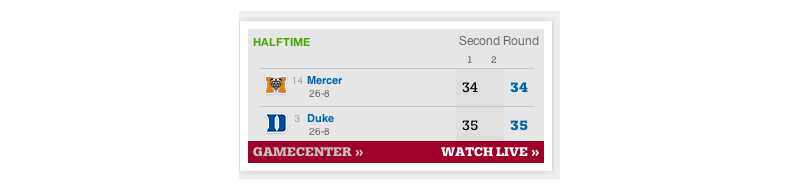
But what we actually care about is the markup under the hood, which looks like this:

If you break down that HTML structure, you can pull out the teams in each game, the score, and the time remaining. We used Node.js and the cheerio module, which makes it easy to write scrapers if you know how to write jQuery for a browser:
var request = require('request');
var $ = require('cheerio');
//Function to call once the page is downloaded
function gotHTML(err, resp, html) {
if (err) return console.error(err);
//Load the HTML into cheerio
var page = $.load(html);
//Find all the <sections> for games in progress
var gamesInProgress = page("section#scoreboard section.game.live");
//For each game in progress, see whether it's a nailbiter
gamesInProgress.each(function(i,game){
var $game = $(game);
var gameStatus = $game.find("div.game-status").text();
//If it's not the second half, do nothing
if (!gameStatus.match(/^2nd/i)) return true;
//This is the clock remaining, like "5:40"
var gameClock = gameStatus.split(" ")[1];
//If there are more than three minutes left, do nothing
if (parseInt(gameClock.split(":")[0]) >= 3) return true;
//Get the teams' current scores
var scores = [];
$game.find("table.linescore td.final.score").each(function(j,score){
scores.push(parseInt($(score).text()));
});
//If the point differential is more than 8, do nothing
if (Math.abs(scores[0]-scores[1]) > 8) return true;
//OK, it's a nailbiter! Next step: compose a nice tweet
//We'll figure this out later
});
}
var url = 'http://www.ncaa.com/scoreboards/basketball-men/d1';
//Download the contents of the scoreboard page
request(url, gotHTML);
Like pretty much all the JavaScript I write, this syntax borrows heavily from Max Ogden.
But there was an insidious problem with this approach. The results seem roughly correct by themselves, but they don’t match what you see in your browser. That’s because the data in the source of the page is actually a few minutes old, and it gets updated right when you load the page (if you refresh that page and look closely, you can see the flash when the numbers change). If we used the scraped data, the bot would be pretty worthless, tweeting “CLOSE GAME WITH THREE MINUTES LEFT!” when the game was actually ending.
This is a common problem when scraping data. The data you want might appear to be “on the page” but often it’s getting loaded in separately using JavaScript. A good way to check whether the data is in the raw HTML of the page is to right-click in your browser and use “View Page Source,” and then search for the same piece of data. If it doesn’t show up there, it means your data is getting mixed in after you load the page.
Fortunately we can put on our detective hats (you do own a detective hat, right?) and trace where the data is actually coming from through the magic of a browser’s developer tools. In Chrome, you can go to Tools > Developer Tools and then click on the Network tab (in Firefox, you can get a similar view at Tools > Web Developer > Network. In either case, you’ll get a console showing you all the OTHER files that your browser is loading in addition to the page itself.
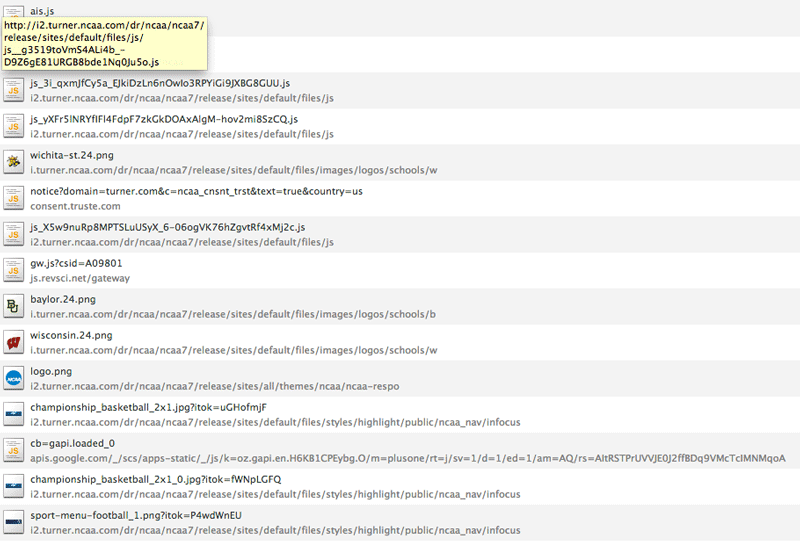
Holy gibberish filenames, Batman! This is another common problem when trying to scrape data: most major websites load about ten billion files on every pageview, everything from images to scripts to ad trackers to stylesheets and more. It can be a lot to sort through. But two tricks can save you from having to manually investigate what’s in each of these files:
- You can filter by file type. We only really care about two types: “XHR” (the most common way data gets sucked in) and “Scripts” (less common). If you only look at each of those types, the list is a lot shorter.
- If a page is updating data automatically without you leaving the page, like this one is, that means it’s getting a new file periodically. If you clear the list and then just wait until the scoreboard updates itself, you should see only the file you care about.
If we do this we eventually find a file that contains all kinds of details about each game:
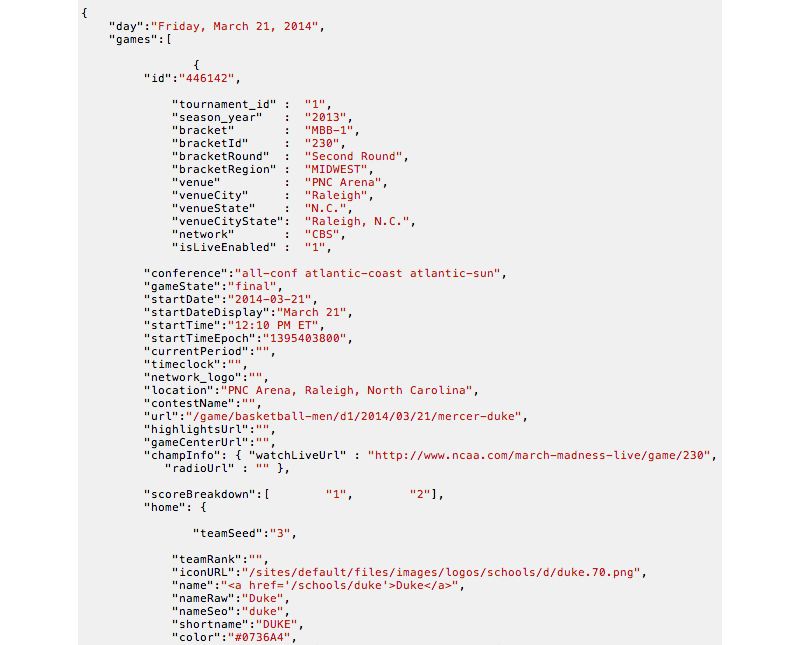
Jackpot! This is a JSON file (technically JSONP), a data format that’s perfect for analyzing with JavaScript.
Identifying Nailbiters
Now that we have the data, our job is a lot easier. We want to revise our script above so that instead of scraping a webpage, it’s using the JSON data and doing similar math to decide whether it’s worth tweeting about:
function gotData(err, resp, gameData) {
if (err) return console.error(err);
//Filter the list down to tweet-worthy games
var nailbiters = gameData.filter(function(game){
//Get the point differential
var diff = Math.abs(parseInt(game.home.currentScore) - parseInt(game.away.currentScore));
//Find the minutes remaining on the game clock, as a decimal number (4:30 = 4.5)
var minutesLeft = parseInt(game.timeclock.split(":")[0]) + (parseInt(game.timeclock.split(":")[1])/60);
//Criteria for time and point differential
var isNailbiter = ((minutesLeft < 3 && diff <= 8) || (minutesLeft < 1.5 && diff <= 6) || (minutesLeft < 0.5 && diff <= 4));
//Only return true if the game is in the 2nd half and meets the time/score criteria
return game.gameStatus == "In-Progress" && game.currentPeriod == "2nd" && isNailbiter;
});
//For each nailbiter, compose a tweet
nailbiters.forEach(function(game){
//Use the NCAA Gamecenter link, current score, etc. to compose a nice tweet
var tweet = {
"url": game.champInfo.watchLiveUrl || null,
"time": game.timeclock,
"network": game.network || null,
"teams": [game.home,game.away].map(function(team){
return {
name: team.shortname,
seed: team.teamSeed,
points: team.currentScore
}
})
};
//Format the relevant info into a sentence
var tweetText = tweet.teams[0].name + " (" + tweet.teams[0].seed + ") v. " +
tweet.teams[1].name + " (" + tweet.teams[1].seed + ") is " +
tweet.teams[0].points + "-" + tweet.teams[1].points +
" with "+tweet.time+" left.";
//Add a link to the NCAA page and TV info if it exists
if (tweet.network) tweetText += "Watch on "+tweet.network+".";
if (tweet.url) tweetText += " "+tweet.url;
//Post the tweet
twitter.statuses(
"update",
{ status: tweetText },
accessToken,
accessTokenSecret,
function(error, data, response) {
if (error) console.log(error);
else console.log("It worked!");
}
);
});
}
Once we fix up a few more wrinkles, like dealing with timezones and making sure the bot doesn’t tweet about the same game more than once, it’s good to go!
What’s Next
We built @NailbiterBot on a whim, but now it’s got me thinking. The @NYT4thDownBot is one of my favorite things in all of journalism, and it’s just scratching the surface. There’s a lot of potential out there for bots with other kinds of situational awareness, including other prospective bots that keep tabs on moments you won’t want to miss. Wouldn’t it be great if baseball fans could get an alert with a link to the audio feed whenever the person on deck had a chance to hit for the cycle, or the winning run moved into scoring position in the 9th inning? By being both creative and specific, we can surface interesting situations with a much higher signal-to-noise ratio than standard news alerts.
People
Credits
-
Noah Veltman
Noah Veltman is a developer and datanaut for the WNYC Data News team. He builds interactive graphics, maps, and data-driven news apps, and spends a lot of time spelunking in messy spreadsheets. Prior to WNYC, he was a Knight-Mozilla OpenNews Fellow on the BBC Visual Journalism team in London. Some of his other projects can be found here.


