Features:
Building an Annotation Tool on a Dime
How we annotated the inaugural address with free and open source tools

Shortly after President Trump’s inauguration, Vox published the inaugural address with annotations from Vox’s policy writers.
Unlike most planned coverage for scheduled events, this whole project went from ideation to completion in a week. A week before the inauguration, Vox’s Director of Programming, Allison Rockey, shared NPR’s live annotation of President Trump’s press conference in our “inspiration” Slack channel and asked if the Storytelling Studio could build something similar for the inauguration.
Given the limited time we had to build the project, we decided to publish the annotation shortly after the inauguration instead of live. We approached this an an experiment in building a live annotation tool that we can iterate on for future events
Getting the Transcript
NPR’s app, which we took inspiration from, is fed by transcriptions coming in from a captioning service that they partner with. At Vox, we do not have a transcription provider we could readily tap into for the annotations app. The first task at hand was to figure out where to get the transcript.
Initial research centered around capturing audio from a video stream and converting it into text. Ryan Mark, Director of Engineering on Storytelling Studio, prototyped a version that uses IBM Watson’s Speech To Text service to pipe the transcript to a Google document.
Further research by Vox Media’s Knight-Mozilla OpenNews Fellow Pietro Passarelli led us to OpenedCaptions, a service created by former OpenNews Fellow Dan Schultz that streams C-SPAN captions in real time over a websocket.
A quick comparison showed us that OpenedCaptions gave us more accurate transcription than our other approaches. We had found our transcription source.
Writing to a Google Doc
We followed in NPR’s steps and used a Google Doc as the main interface for annotating the inaugural address.
Our next challenge was to figure out how to get the captions into a Google document where the writers could add their annotations. The obvious choice was to use Google Apps Script to pull the live captions from OpenedCaptions. However, apps script does not support sustaining connections to a websocket endpoint like the one provided by OpenedCaptions. An apps script can only be run once a minute.
Ryan and Pietro built an intermediate server to buffer the transcript from OpenedCaptions and make it available as a REST API. The server was deployed to Heroku and used in-memory cache to buffer the captions.
The intermediate server also made some optimizations to reduce the copy editing overhead by converting all uppercase captions from OpenedCaptions to sentence case. To help with this process, the team pitched in to identify a list of potential proper nouns and entities and the proper casing for it.
We now had captions “streaming” into the Google document. While this was not strictly real time, it was close with only a minute lag.
Annotation Markup
We had to create a system of notations to use to differentiate the annotations from the transcript. The system had to be simple to reduce the overhead annotators and editors would face.
We came up with a square brackets–based annotation markup system.
Any text included in double square-brackets identified by regex /.*(\[\[(.*)\]\]).*/ was highlighted.
Any line that started with a writer’s initials in single square brackets (regex: /(\[(..)\]\s*:\s*)(.*)/) was treated as an annotation. The initials were then matched against a list of writers to fill out name and twitter handle.
Any line that had an image url followed by text was converted into markup for image and caption.
Editorial Workflow for Annotations
Using Google Docs as the main interface—an interface reporters are already familiar with—for adding annotations reduced the learning curve. Just like at NPR, the reporters added annotations in Suggesting mode in the document which the editors then approved to mark it as ready for publishing.
The team documented the editorial workflow and annotations. The document was made available to reporters to refer to as they were adding notations.
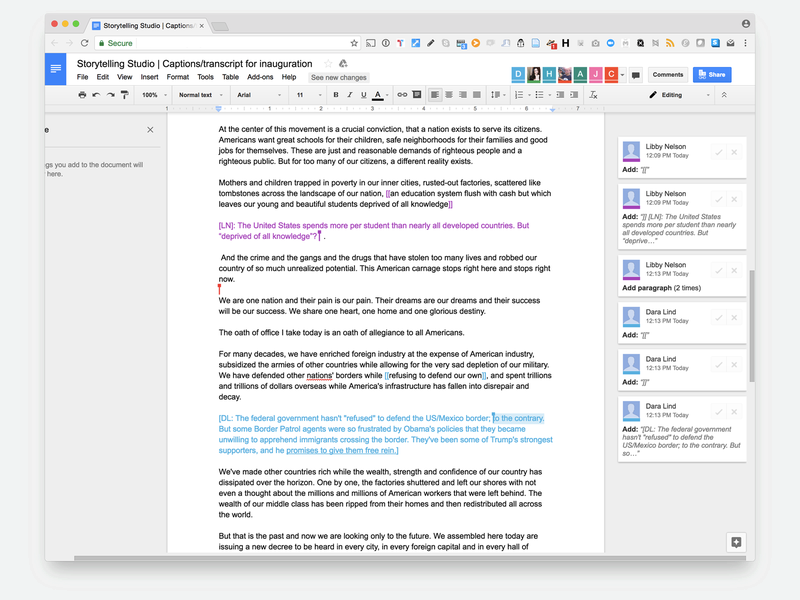
A snapshot of our annotation writing/editing process, in progress.
Publishing the App
The Storytelling Studio team routinely uses documents and spreadsheets on Google Drive in our apps, so we have very well established processes and tooling for building the frontend app to publish the content in the doc.
Like most of our apps, the annotation tool is a Middleman app. It uses Vox Media’s middleman-google-drive gem to get the content of the Google Doc into the application.
While the backend was being built, Storytelling Studio’s Design Director Kelsey Scherer designed the app to work both on the Vox.com site as well as on Google’s AMP. The annotation markup from the Google Doc was manipulated into the right HTML markup and it was published to the site.

An example of an annotation, as it appeared on the site.

How an annotation looked, within the flow of the transcription.
Iterating on the System
Even though we decided to not publish it live, we approached it as a dry run for real-time publishing. The copy editors, writers and annotation approvers all worked on the document as if it were being published live. We internally updated the app on a regular interval.
The Storytelling Studio is now making updates to the system to better support real-time publishing. We are also looking into pulling transcriptions from other sources.
Setting It up in Your Newsroom
We used free and open source libraries and systems to get this annotation service up and running in a very short time. Here is a handy list if you are interested in setting up something similar in your newsroom:
People
Organizations
Credits
-
 Kavya Sukumar
Kavya Sukumar
Kavya is a developer with a journalism habit. She joined Vox Media’s Storytelling Studio as an OpenNews fellow in 2015 and stayed on after her fellowship. Her first newsroom job was with the investigative team at the Palm Beach Post. Before that she was a developer at Microsoft.


