Features:
Launching the Minnesota Legislative Bill Tracker
From the team at MinnPost

This week, statewide, nonprofit news site MinnPost released a new project to track legislation at the state level. The team behind the project told Source a bit about how it took shape.
Project Origins
Q. How did the project get started?
As we anticipated the 2013 legislative session, we wanted to offer readers an easily accessible way to get information about the Minnesota legislative process as it happened. When we discussed priorities, our team decided to focus on two primary user questions: What is the legislature actually doing? and Why does it matter to me?
We knew that we could use Open States’ excellent API for up-to-date data on specific legislation. But with over 3,000 bills already introduced in the first month of the session, we needed to add a layer of editorial judgment to highlight the most important bills and tell readers why they are important. Which is exactly what MinnPost’s political reporters do best.
That’s how we landed on this hybrid of automated Open States data with a layer of reported information that adds context and clarity to the raw data.
Q. Is the workflow for this project similar to other projects at MinnPost? How much staff time is it taking?
The workflow for this project was fairly similar to other work that we do—we loop in editors and the appropriate reporters from the beginning, and throughout the process to make sure we’re on the right track.
The legislative tracker definitely took a bit more editorial work on the front end—writing bill and category summaries, gathering story links, etc.—but we built it to be easily updated and require only moderate maintenance during the rest of the session. Open States will provide the live bill updates, and our reporters can add links and updates as needed.
How It Works
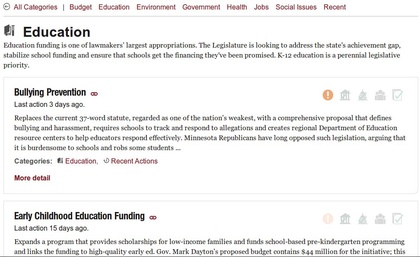
Browsing relevant bills by category.
Q. The GitHub repo for the Legislature Tracker shows it’s built from data from Open States and editorial data stored in Google Docs. Could you walk us through how that was built and how you work with the data?
We have two main data sources for this project: the raw data of legislative updates from Open States and the editorial expertise provided by our political reporters (namely James Nord and Beth Hawkins).
The Minnesota Legislature does have bill data on its website, but it does not provide the data in a structured way via an API, which means we cannot use it directly in our application. Fortunately, Open States scrapes the website and creates a nice API for anyone to use.
For the editorial data, we needed to create our own data source from scratch. We’ve found that Google Spreadsheets is an accessible interface for our reporters and editors to input data, and simple for us to use as a data store.
The application pulls these two data sets together in an interface that’s easy for our readers to explore.
Q. Did you work closely with the Open State/Sunlight folks? What’s the workflow like on the editorial side?
The folks at Sunlight Labs that work on Open States are really amazing and helpful. Since this was a new session and web scraping is a volatile activity, there were some missing bits of data from the Open States API as the Minnesota Legislature site had changed. They were incredibly responsive in fixing these parts, often updating them within a day of us reporting them.
On the editorial side, reporters can edit the Google Spreadsheet directly whenever they have relevant updates and the application reflects those changes automatically minus some caching times.
Q. What other tools did you build to support the Legislature Tracker?
Besides working with and building on existing projects like Open States and Tabletop.js (which powers pulling data down from Google spreadsheets), we built a couple standalone projects to support this one. These projects are focused around proxying and caching requests so that the application is as speedy as can be.
We built a simple application that proxies and resizes images, specifically from the MN legislature. This arose from the fact that Open States images for legislators are the original image and often extremely large. This slows down loading times for the images and the application as a whole. We built a small application that can be deployed on Heroku that ensures only smaller thumbnails can be loaded. The code is technically set up for the Minnesota Legislature only, but could easily be changed to proxy any images.
The second project we built to supplement the Legislative Bill Tracker is a very simple proxy and cache server for Google Spreadsheets requests. Google Spreadsheets are very powerful, but they are limited by Google’s request limits which are a bit hard to predict but will almost certainly cause problems in a production environment. Some people get around this issue by downloading the API responses to places like S3, but due to the fact that Tabletop actually uses many requests to the Google Spreadsheets API and emulating that structure seemed brittle, we went with an actual proxy server that would cache things locally.
GS-Proxy is meant to be really simple to deploy on Heroku, just set the keys to your Google Spreadsheets and how long you want to cache and you are good to go.
Q. How does this project work with your Drupal content management system?
We handle most of our interactive projects by embedding HTML/CSS/JS directly into a raw code field in the CMS. We try very hard to not have server components for our projects so embedding the project directly in the page is not an issue.
With this project we experimented with a build process powered by Grunt.js which compiled all the code and uploaded it to S3. This meant that our code and styles could be separated into multiple files as they should be, while making the interactive easier to update, and gaining performance from minimizing code.
Looking Ahead
Q. Are there parts of the project that you’re still developing?
Our reporters will continue to update the tracker throughout the session with political insight and context. We’d also like to implement new features as we have time, such as the ability to subscribe to or share a specific bill.
Q. Are there plans for the project to continue beyond the 2013 legislative session?
This is a project we aim to use for each legislative session. I think it is at a good point for our use during the current session, but with each iteration we plan to improve it.
Our team member, Alan Palazzolo, will be participating in ProPublica’s P5 program later this month, during which he’ll spend time making this application reusable for other newsrooms. We built the application with this goal in mind, but due to deadlines there is still plenty of work to be done to make this a reality.
Q. Any lessons that you’d share with other organizations working on similar statewide projects?
We’ve seen a few similar projects, like at the WFC Courier, which just demonstrates the need for this sort of application. Services like Open States provide much-needed structured data, especially considering the huge amount of information involved with state legislatures, but making that data relevant to a larger audience requires expertise and editorial judgment.
The legislative bill descriptions are often jargony and hard for the average reader to parse. They don’t tell you if this bill has failed to pass three years in a row, or whether it’s a pet project of the governor. To promote transparency and offer value to our readers, we need to provide data with some sort of context—so that citizens can understand why a piece of legislation is important and how it could affect their lives.
People
Organizations
Code
Credits
-
Beth Hawkins
-
 Kaeti Hinck
Kaeti Hinck
Kaeti Hinck is an editor at The Washington Post, where she leads an award-winning visual journalism team and explores the intersection of technology, design, and narrative. Before joining the Post in 2016, she worked as design director of the Institute of Nonprofit News. At INN, she helped design and build open source products to support independent publishers. For more than a decade she has been exploring the power of visual communication and technology in newsrooms. Outside of work, you’ll likely find her reading under a blanket, searching for the perfect breakfast sandwich, and spending as much time in the woods as possible.
-
Tom Nehil
-
James Nord
-
 Erika Owens
Erika Owens
Co-Executive Director of OpenNews.
-
Alan Palazzolo


